
20240808 TIL
1. 머신러닝
- 기술 통계 등을 통하여 집계된 정보로 의사결정을 했던 과거와 달리 데이터 수집과 처리 기술의 발전으로 대용량 데이터의 패턴을 인식하고 이를 바탕으로 예측, 분류하는 방법론
머신러닝이 발전한 이유 - 인간은 데이터를 기반으로 한 의사결정을 내리고 싶기 때문
▶ 머신러닝 종류

- 지도 학습
- 비지도 학습
- 강화 학습
2. 선형회귀 이론
- 공통
- Y는 종속 변수, 결과 변수
- X는 독립 변수, 원인 변수, 설명 변수
- 통계학에서 사용하는 선형회귀 식
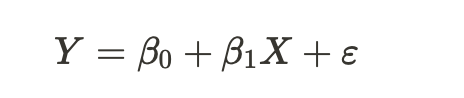
- 베타0 : 편향(Bias)
- 베타1 : 회귀 계수
- 마지막 : 오차(에러), 모델이 설명하지 못하는 Y의 변동성
수식 계산 - 각 변수가 사실 행렬로 이루어진 값

머신러닝/딥러닝에서 사용한느 선형회귀 식
Y = wX + b- w: 가중치
- b: 편향(Bias)
*머신러닝/딥러닝 모델에서 오차 항은 명시적으로 다루지 않음
∴ 두 수식이 전달하려고 하는 의미는 같다 회귀 계수 혹은 가중치 값을 알면 X가 주어졌을 때 Y를 알 수 있다.
(편의를 위해 X의 계수는 가중치라 지칭!)
Q1) β0는 1차 방정식의 Y절편에 해당하는 걸 알겠어요. 그런데 \varepsilon(3반대모양)은 왜 따로 있는건가요?
우리가 몸무게와 키에 대한 선형회귀식을 만들었지만, 해당 식이 모든 데이터를 완벽하게 설명할 수 없다.
이때 완벽한 설명이란 실제 데이터값 = 예측 데이터 이라고 할 수 있다
다시 말해 에러(②,③)의 값을 표현하기 위해서 있는 것
Q2) 가중치($w)$를 알게 되면 X값에 대하여 Y값을 예측할 수 있다는 것은 이해가 되는데, 그럼 가중치는 어떻게 구하죠?
이런 물음이 들었다면 머신러닝을 관통하는 질문!
데이터가 충분히 있다면 가중치를 “추정”할 수 있다.
이 부분은 현재는 그래프를 수도 없이 그려서 에러를 “최소화”하는 직선을 구한다고 생각
'✨Today I Learned' 카테고리의 다른 글
| 머신러닝 기초: 로지스틱 회귀 (1) | 2024.08.13 |
|---|---|
| 머신러닝 기초 : 회귀분석 기초, 심화 (2) | 2024.08.09 |
| 데이터 리터러시 (0) | 2024.07.03 |
| SQL 라이브 3일차 숙제 (1) | 2024.06.28 |
| SQL 라이브 세션 1~2일차 숙제 (0) | 2024.06.27 |