
원문 : https://yozm.wishket.com/magazine/detail/1816/
그 데이터는 잘못 해석되었습니다 | 요즘IT
무엇이든 데이터가 있으면 쉽게 결정을 내릴 수 있을 것 같습니다. 하지만 현업에서는 데이터가 있어도 결정을 내리기 어려운 상황들이 있습니다. 특히 데이터를 통한 의사결정을 내릴 때, 가장
yozm.wishket.com
➕ 아티클 요약 및 주요 내용
요약 :
<데이터를 잘못 해석하는 상황별 유형>
1. 생존자 편향의 오류: 전체 이용자를 기준으로 한 것이 아닌 이탈자를 대상으로 한 실패
- 무사귀환한 전투기 대신 전체 전투기를, 이탈한 유저 대신 전체 활성화된 유저를 기준으로 해석을 시도하면, 올바른 지표에 따른 해석 가능
2. 심슨의 역설: 부분 집합의 결과가 전체 집합의 결과와 반대되는 현상.
예시) 참고 사이트: https://medium.com/bondata/simpsons-paradox-and-confounding-190a26f9e039
@ covid-27 라는 새로운 질병 발병
@ 목적은 환자의 사망률을 가장 낮추는 백신을 선택해 수입하는 것
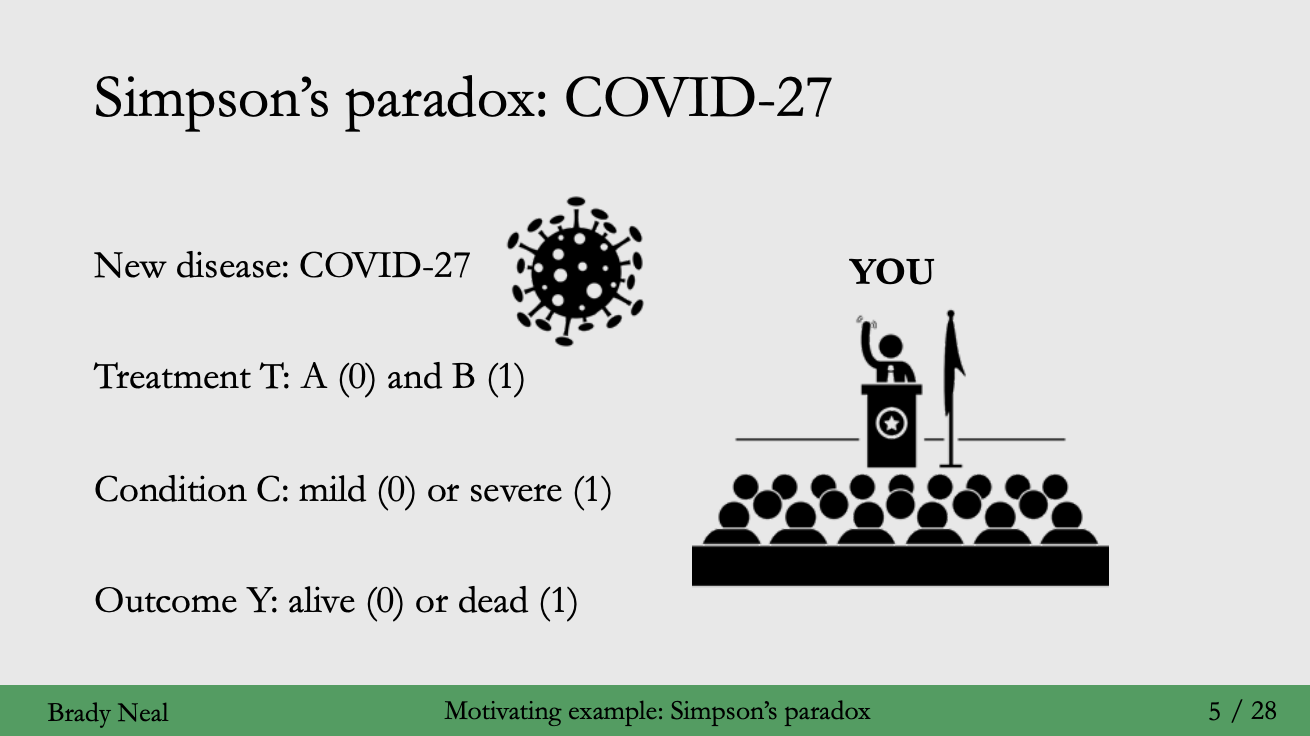
- 이 백신은 Treatment 라고 칭하고, A와 B로 2가지가 존재
- 백신 A보다 B가 개수가 더 모자라서 희귀
- 백신을 맞게 될 환자들은 mild, severe 두 가지 상태로 분류되고,
- 백신을 맞게 되었을 때 결과로 가능한 환자의 상태는 outcome --> alive, dead
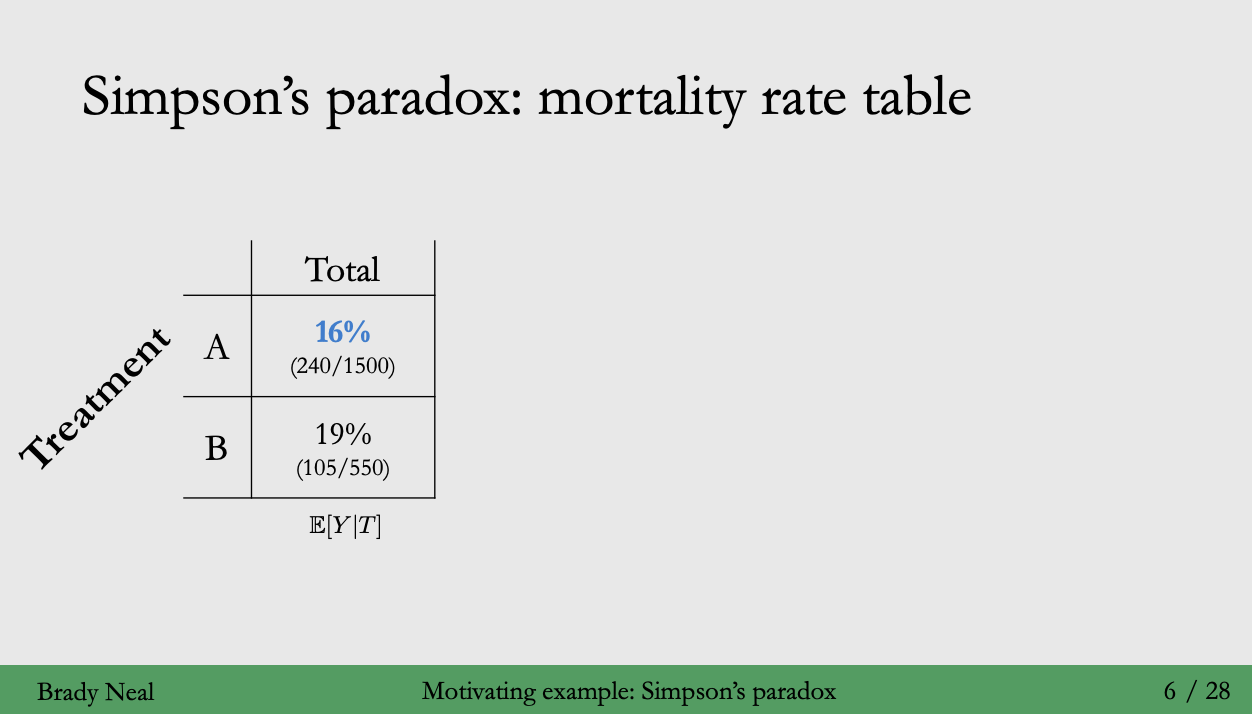
-전체 그룹을 묶어 비교했을 땐 사망률이 더 낮은 A를 선택해 수입하는 것이 맞음
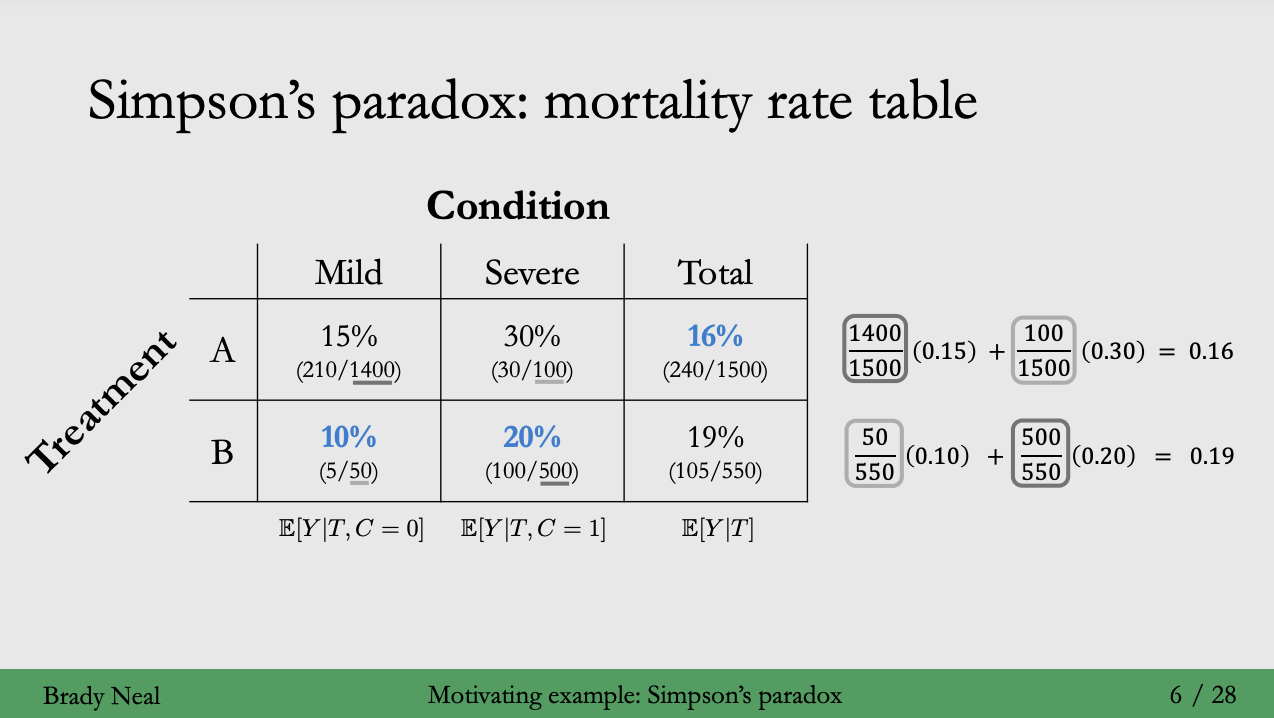
환자의 상태에 따라 사망률이 뒤바뀌는 결과
- mild 한 상태였던 환자 : B가 더 낮은 사망률을 보임 // - severe 한 상태였던 환자 : 백신 B가 더 낮은 사망률
개별 그룹에서 백신의 효과를 비교했을땐 A < B가 효과적!
그러나 전체 그룹을 합쳤을 땐 A > B 가 효과적
-----> 이러한 현상을 심슨의 역설(Simpson's Paradox)
원인?
1. A는 mild 상태인 환자가 1500명 중 1400명으로 93% 차지
2. B는 severe 상태인 환자가 550명 중 500명으로 91% 차지
즉, 그룹을 구성하는 상태(condition)의 가중치 때문에 그룹 전체 평균을 냈을 때 숫자의 왜곡이 발생했기 때문
3. 상관관계와 인과관계: 상관관계가 반드시 인과관계를 의미하지 않음을 주의
<예시>
이벤트 페이지의 조회수 지표가 증가/감소하는 경향성과 매출 지표가 증가/감소하는 경향성이 비슷할 때
--> 매출이 최종적으로 도달하고자 하는 목표이기 때문에 이벤트 페이지 조회수가 매출에 영향을 준다는 결론으로 이어지기 쉬움
이처럼 상관서은 있으나 인과성이 없는 경우는 제3의 공통 원인이 존재할 가능성 ↑
두 지표의 공통 원인 - 매력적인 이벤트
매력적인 이벤트를 할 때, 이벤트 조회수 ↑, 매출 ↑
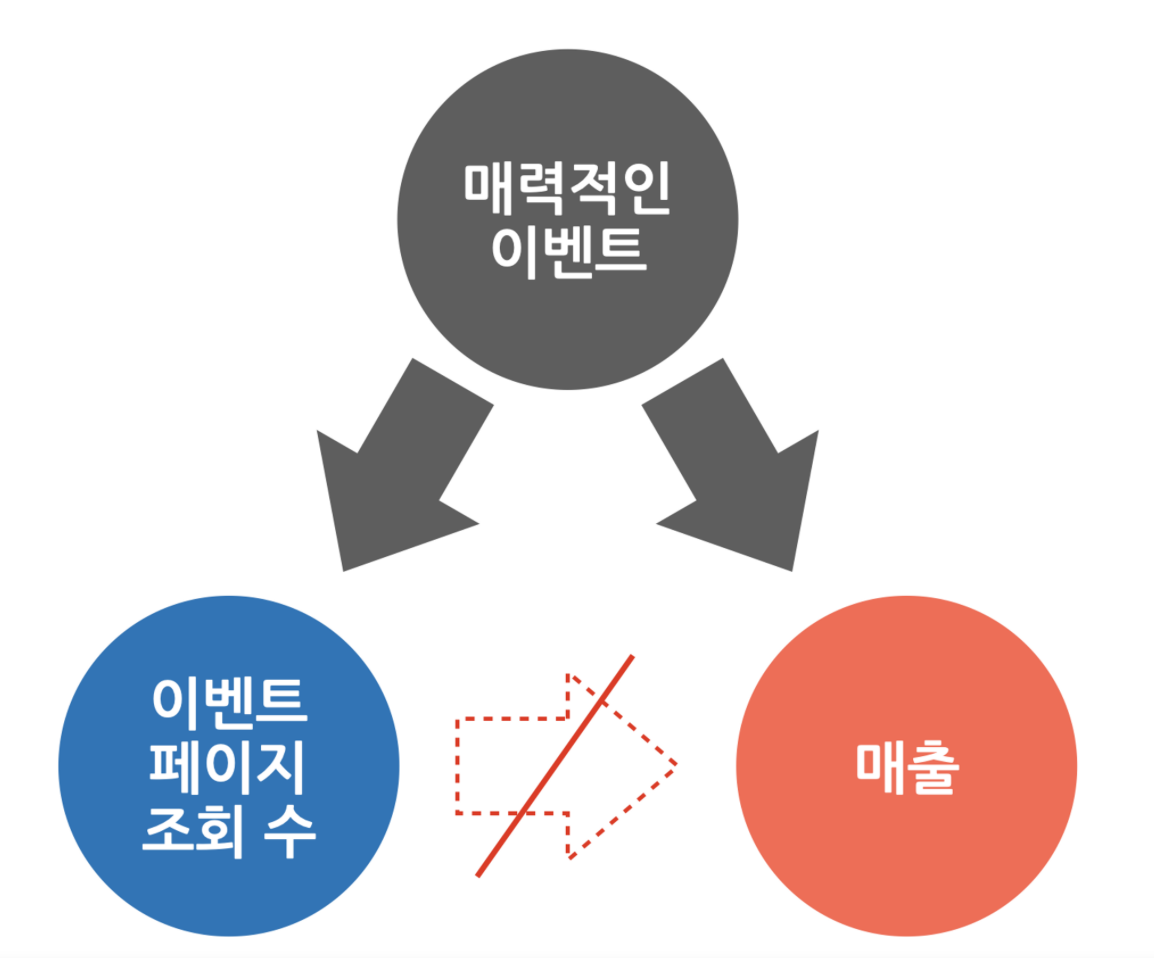
∴ 이벤트 페이지를 많이 보게 하면 매출이 늘어난다는 결론 대신, 매력적인 이벤트를 하면 매출이 늘어난다를 결론을 내려야 함!
4. 목적에 맞지 않는 지표 선택 : 분석 목적에 적합한 지표 사용하기
세이건 표준 참고하기:
데이터는 가공하는 기준과 방법에 따라 바뀔 수 있고, 데이터를 해석하는 사람의 생각이 반영 가능
--> 이러한 이유로 데이터가 잘못 해석된다면 잘못된 방향으로 이어질 수 있음
그렇기 때문에, 데이터를 잘못 해석하지 않기 위해선 칼 세이건의 세이건 표준을 참고하면 좋음
특별한 주장에는 특별한 근거가 필요하다. (Extraordinary Claims Require Extraordinary Ecidence, ECREE) - 칼 세이건의 '세이건 표준'
주요 포인트 :
- 주요 오류로는 생존자 편향, 심슨의 역설, 상관관계와 인과관계 혼동, 목적에 맞지 않는 지표 선택이 있으며, 이를 방지하기 위해서는 정확한 데이터 분석과 신중한 접근이 필요
➕ 핵심 개념 및 용어 정리
핵심 개념 :
- 데이터 해석의 중요성: 잘못된 해석은 잘못된 결론을 초래할 수 있음.
- 명확한 목적 설정: 분석 목적에 맞는 정확한 지표를 선택해야 함.
- 세분화된 데이터 분석: 전체 데이터를 기준으로 다양한 각도에서 분석 필요.
- 목적에 맞는 지표 선택: 분석 목적에 적합한 지표 사용.
용어 정리:
- 상관관계 : 서로 영향을 주고받는 관계
- 인과관계 : 원인과 결과의 관계
- 지표 : 성과정도를 측정하거나, 프로그램에 따른 개입활동과 관련된 변화를 반영하며, 또는 행위자의 활동성과를 측정할 수 있도록 하는 간단하면서 신뢰할 만한 수단으로써의 기능을 하는 정량적/정성적 요소 또는 변수
➕ 실무 적용 사례
P.5~7에 빅데이터 프로젝트의 실패 사례가 나옴
- 구글 전염병 예측 서비스 'GFT' (Google Flu Trends)
- 테스코의 정량 데이터 고집(TESCO)
-'이루다' 챗봇 혐오발언 논란 ( SCATTER LAB)
- 미 부동산 기업 '질로우'의 주택가격 예측 오류 (Zillow)
이 외 내용은 기업이 데이터 분석에 성공하기 어려운 이유에 대해서 설명하는데 한 번쯤 읽어봐도 괜찮을 것 같다!
➕느낀 점
데이터를 사용하면서 우리에게 주는 어떠한 이점이 있지만 데이터에 대해서 무한한 신뢰를 가지면 안될 것 같다고 생각했다.
좋지 않은 데이터를 수집하면 의미가 없듯이 무조건 데이터를 많이 수집한다고해서 좋은 것은 아닌 것 같다. 아티클에서 나온 주요 오류들을 잘 생각하면서 정확한 데이터 분석과 신중한 접근이 필요할 것 같다. 그리고 효정님께서 아티클에 나온 오류들 말고도 다른 오류들도 참고로 넣어주셔서 어떤 오류들이 있는지 더 자세하게 알게되었다.
'아티클스터디' 카테고리의 다른 글
| 아티클 스터디 : 빅데이터 시대, 성과를 이끌어 내는 데이터 문해력 3장 (0) | 2024.07.24 |
|---|---|
| 아티클 스터디 : 빅데이터 시대, 성과를 이끌어 내는 데이터 문해력 1장/2장 (0) | 2024.07.22 |
| 아티클 스터디 : 데이터 분석가가 되어보니 중요한 것들 (0) | 2024.07.15 |
| 아티클 스터디 : SQL 질문 잘 하는법 (0) | 2024.07.10 |
| 아티클 스터디 : 데이터 기반 의사결정 장점 (1) | 2024.07.08 |