
20240823 TIL
심화 프로젝트 start! -
기초 프로젝트에서 머신러닝 기법만 추가된 심화 프로젝트이다!
아직 머신러닝 공부가 제대로 안돼있어서 걱정이 되긴 하지만 화이팅!
1. 주제 선정
[회귀] 이커머스 주간 판매량 예측으로 선정하게 됐다.
https://teamsparta.notion.site/88a9ef95797147e7b741260b406da6f3
[회귀] 이커머스 주간 판매량 예측 | Notion
프로젝트 제목
teamsparta.notion.site
<선정 이유>
아무래도 우리 팀이 비전공자들이 모여있어서 가장 많이 접할 수 있었던 것을 선택을 했는데 그것이 주간 판매량 예측이었다.
또, 페이지 자체에도 설명이 잘 돼 있었고 찾아보니 데이터도 실제 캐글에서 대회가 열렸었던 것이라서 데이터 분석할때 다른 주제들보단 쉽게 해낼 수 있을 것 같다고 생각했다.
[프로젝트 명]
효율적인 재고 관리를 위한 주간판매량 예측
[프로젝트 목표]
주간 판매량을 예측하여 매출증대 및 운영 비용 절감을 목적으로 합니다.
[프로젝트 핵심내용]
회귀를 통해 모델을 학습, 평가 , 최적화를 진행하겠습니다.
2. 데이터 뜯어보기
https://www.kaggle.com/c/walmart-recruiting-store-sales-forecasting/data
Walmart Recruiting - Store Sales Forecasting | Kaggle
www.kaggle.com
<features.csv>
- Store - the store number
- Date - the week
- Temperature - average temperature in the region
- Fuel_Price - cost of fuel in the region
- MarkDown1-5 - anonymized data related to promotional markdowns that Walmart is running. MarkDown data is only available after Nov 2011, and is not available for all stores all the time. Any missing value is marked with an NA.
- CPI - the consumer price index
- Unemployment - the unemployment rate
- IsHoliday - whether the week is a special holiday week
<sampleSubmission.csv>
<stores.csv>
- 상점의 유형과 크기를 나타내는 45개 상점에 대한 익명의 정보가 포함
<test.csv>
- 주간 판매를 보류한 것을 제외하고는 train.csv와 동일, 이 파일에서 상점, 부서 및 날짜의 각 세 배의 판매를 예측해야 함
<train.csv>
- Store - the store number
- Dept - the department number
- Date - the week
- Weekly_Sales - sales for the given department in the given store
- IsHoliday - whether the week is a special holiday week
총 데이터가 5개가 있었기 때문에 이 중에 뭘 써야할지 생각을 했었어야 했다.
처음부터 이런 난관에 봉착해 아 ... 쉽지 않을 걸 선택했구나를 깨달았다 ^^ ..... 그래도 이왕 선택한거 잘 해결해보잔 마인드로 시작했다
어떤 데이터를 써야할지 막막해서 우리팀은 튜터님께 여쭤봤고 튜터님께서 train, store, features를 결합해서 다시 하나의 데이터를 만들어서 사용하라고 했다.
3. 데이터 전처리
- 데이터 불러오기 및 타입 변환, 데이터 결합
# 데이터 불러오기
import pandas as pd
features = pd.read_csv('/Users/minjungim/Documents/심화프로젝트/features.csv')
stores = pd.read_csv('/Users/minjungim/Documents/심화프로젝트/stores.csv')
train = pd.read_csv('/Users/minjungim/Documents/심화프로젝트/train.csv')
test = pd.read_csv('/Users/minjungim/Documents/심화프로젝트/test.csv')#Date의 타입을 datetime으로 변경합니다.
features['Date'] = pd.to_datetime(features['Date'])
train['Date'] = pd.to_datetime(train['Date'])
test['Date'] = pd.to_datetime(test['Date'])# 데이터 결합(merge)
merged = train.copy()
merged = merged.sort_values(by=['Store','Dept','Date'])
mf = features.merge(stores, how='inner', on=['Store'])
merged = pd.merge(merged, mf, how='inner', on=['Date','Store','IsHoliday'])
merged.head(3)<결과 값>

이렇게 결합까지 해준 다음, 데이터에 어떤 정보가 있나 확인해줬다.
# 데이터 확인
merged.info()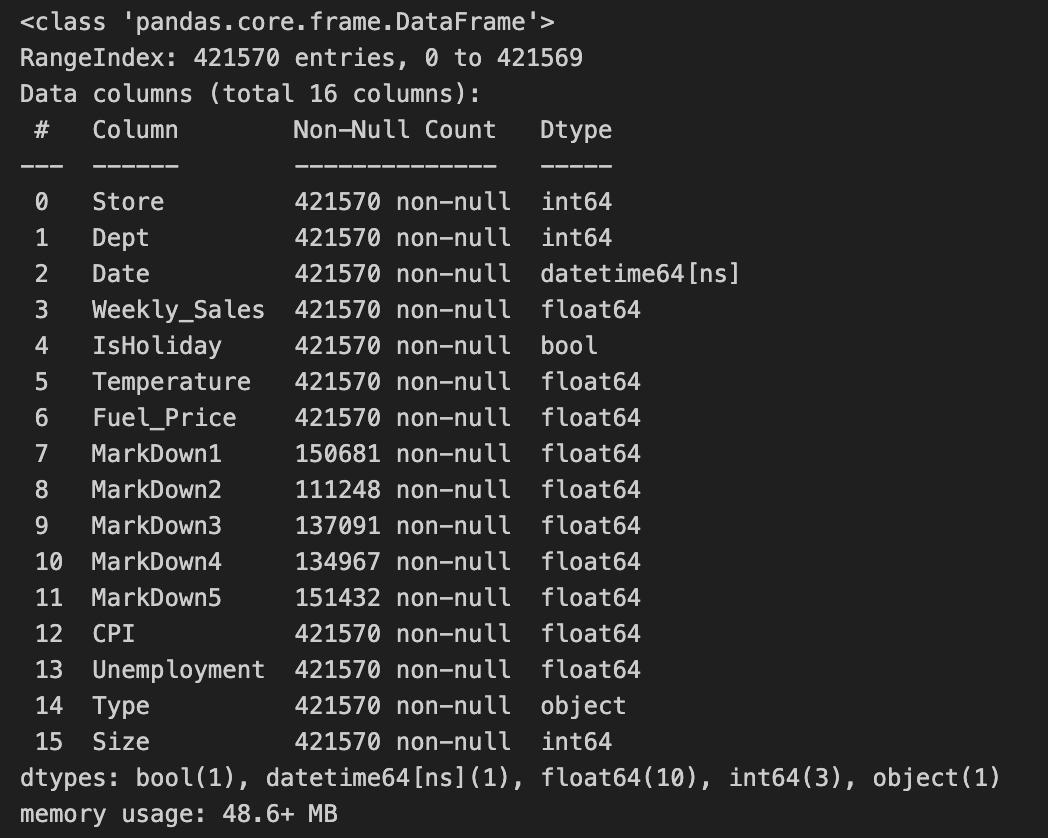
나머지는 결측치가 없지만 markdown1~5까지 결측치가 있어서 다시 얼마나 결측치가 있는지 isnull().sum()을 통해 다시 한 번 확인 해줬다.
- 결측치 확인 및 대치
merged.isnull().sum()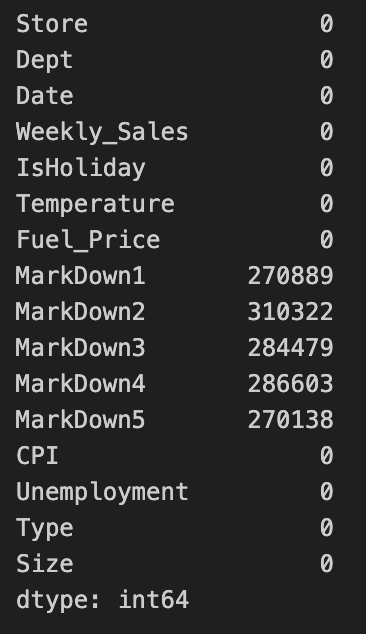
꽤 많은 결측치가 보였고 전체 총 몇개의 데이터가 있는지 다시 확인 해봤다.
merged.shape
#(421570, 16)총 4만개 정도의 데이터가 있었고 그 중 마크다운1~5가 이만 후반에서 삼만까지 결측치가 있었다.
거의 50%가 넘는 결측치가 있었지만 우리는 나중에 혹시 주간 판매량 예측에 사용할 수도 있어 제거하기 보단 대치하기로 했다.
마크다운이 어떤 건지 설명을 보면 홍보 관련 데이터라고 나와있길래 결측지가 있던 건 홍보하지 않음으로 생각하여 가장 일반적인 0으로 대치했다.
# markdown은 홍보와 관련된 익명화된 데이터이며, 모든 상점에 사용할 수 있는 데이터는 아니기 때문에 누락된 값을 0으로 대치
merged[['MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4', 'MarkDown5']] = merged[['MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4', 'MarkDown5']].fillna('0')
merged.head(3)
잘 변환됐고 다시 한 번 결측치가 있나 확인을 해봤다
# 다시 결측치 확인
merged.isnull().sum()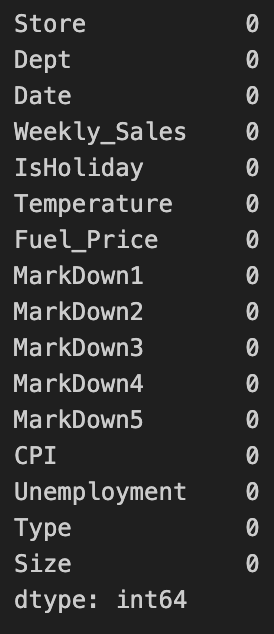
이렇게 결측치가 다 0이 됐기 때문에 결측치 처리는 완료!
- type 컬럼 object -> bool
그런 다음 아까 Info()에서 type이 object형이었기 때문에 원핫인코딩을 통해 바꿔준다.
바꾸는 이유?
Object형 데이터는 주로 문자열 데이터를 포함하며, 머신러닝 모델은 이러한 데이터를 직접 처리할 수 없다
모델은 숫자형 데이터를 이해하고 계산하는 데 적합하기 때문에, object형 데이터는 숫자형으로 변환해야 하기때문!
원핫인코딩은 범주형 데이터를 이진 벡터로 변환하여 각 범주를 숫자 형식으로 나타내는 방법이고 모델이 범주형 변수의 정보를 사용할 수 있게 되는 것
#Type이 object형이어서 원핫인코딩을 진행
df = pd.get_dummies(merged, columns=['Type'],drop_first=True)
#다시 확인
df.info()- pd.get_dummies: 이 함수는 범주형 변수를 이진 벡터로 변환하는 것. 예를 들어, Type 열에 'A', 'B', 'C'라는 값이 있다면, 각각에 대해 별도의 열을 만들어 1 또는 0으로 표시
- columns=['Type']: Type 열을 대상으로 원핫인코딩을 수행하겠다는 의미
- drop_first=True: 첫 번째 범주를 제거하여 다중공선성 문제를 방지
<확인 결과>


- Date 를 Month로 변환
왜 바꾸는지?
Date열을 월로 변환하여 새로운 열을 추가하는 것은 주간 판매량을 예측하는 데 유용할 수 있기때문
(주간으로 변경하면 또 많은 데이터가 생길까봐 월 별로 변환을 선택)
어쨌거나 저쨌거나 변환을 시켜주는 것이 예측을 향상시키는 것에 도움
# Date 열을 월로 변환
df['month'] = df['Date'].dt.month
df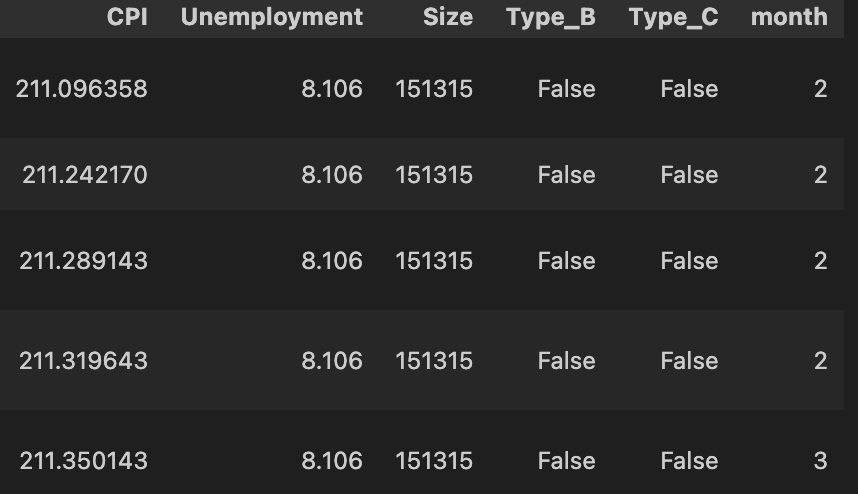
이렇게 마지막에 월별로 나오게 됨
-상관관계 확인
df.corr()- Dept, Size, Type은 weekly sales와 약한 상관관계
- markdown1-5는 상관관계가 거의 없다
- temperature, fuel_price, CPI, unemployment도 상관관계가 거의 없다
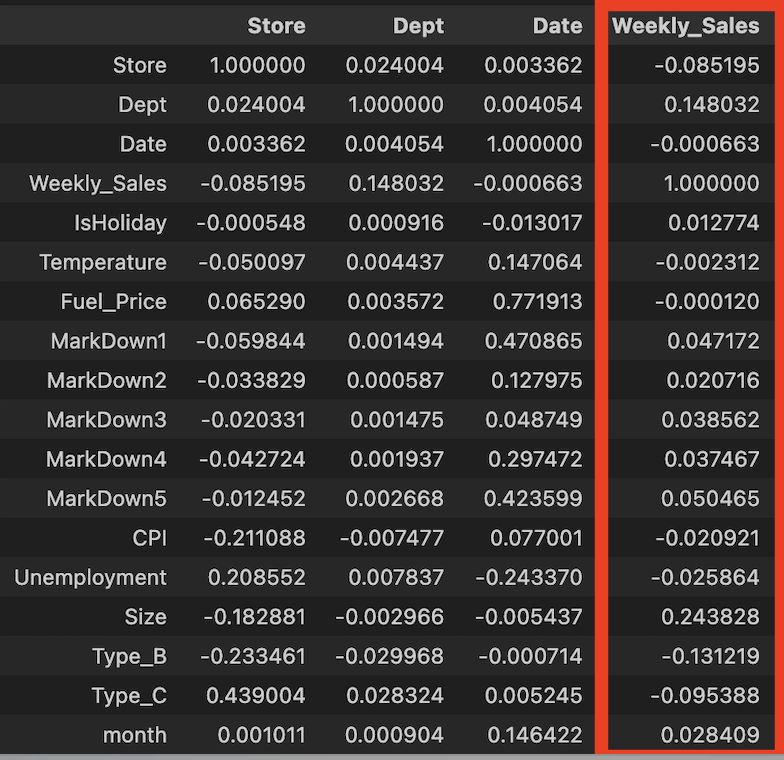
좀 처참한 상관관계를 보고 잘 해낼 수 있을까...란 생각을 했다.. 낮아도 너무 낮은거 아니냐고 .. ㅠㅠ
그래도 정해진 데이터에서 어떻게서든 주간 판매량을 예측하고 머신러닝 모델까지 돌려봐야했기에 그냥 진행하기로 했고 여기서 최대한 선능을 향상 시키는 쪽으로 하기로 했다.
또 내가 배운 것을 가지고 실습을 하는 거기 때문에 너무 부담감도 가지지 않으려고 했다
그래서 그냥 진행 -!
- 무작위 표본 추출
다른 팀원 분 중에 현재 우리가 가지고 있는 데이터가 너무 커 머신러닝을 돌렸을때 실행이 되지 않고 로딩만 된다고 했다
그래서 튜터님께 여쭤본 결과 사만개 정도의 데이터면 그럴 수 밖에 없다고 하셨고(일반 컴퓨터 가정) 그래서 추천 받은 것이 무작위 표본 추출을 해서 만개로 줄여 사용하는 것이었다. 그래서 바로 진행 !
# 단순 무작위 표본 추출 -- 데이터를 무작위로 만개 추출
sample_data = df.sample(n=10000, random_state=42)
sample_data이런 다음 shape를 통해 줄어들었는지 확인해봤다.
sample_data.shape
#(10000, 18)만개로 잘 줄어들었다!
- 변수 중요도 구하기
상관관계를 봤을때 거의 다 비슷비슷했기에 우리가 어떤 변수들을 최대한 이용하는게 좋을까 싶어 변수 중요도를 구해봤다
변수 중요도를 구하는 방법을 사실 몰랐는데 같은 팀원인 지완님께서 먼저 진행해주셔서 볼 수 있었다
#샘플들을 가지고 변수 중요도를 구하기
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(sample_data.drop(['Date','Weekly_Sales'],axis=1), sample_data['Weekly_Sales'], test_size=0.3, random_state=42)
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
# 랜덤 포레스트 모델 생성 및 학습
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)
# 변수 중요도 추출
importances = model.feature_importances_
# 변수 중요도를 데이터프레임으로 정리
importance_df = pd.DataFrame({'Feature': X_train.columns,'Importance': importances}).sort_values(by='Importance', ascending=False)
print(importance_df)1. 우선 train_test_split을 통해 데이터를 분할
- sample_data에서 Date와 Weekly_Sales 열을 제외한 모든 열을 특징으로 사용, Weekly_Sales를 타겟으로 설정하여 데이터를 학습용(X_train, y_train)과 테스트용(X_test, y_test)으로 70:30 비율로 나누기(test_size=0.3)
2. 랜덤포레스트 모델 생성 및 학습
- RandomForestRegressor 모델을 생성하고 학습 데이터(X_train, y_train)로 모델을 학습
- 랜덤 포레스트 - 여러 개의 결정 트리를 결합하여 예측을 수행하는 앙상블 학습 방법
3. 변수 중요도 추출
- model.feature_importances_는 학습된 랜덤 포레스트 모델의 각 특징에 대한 중요도를 나타내는 배열
- 이 배열의 길이는 입력 데이터의 특징 수와 동일하며, 각 값은 0과 1 사이의 숫자로 표현
4. 변수 중요도를 데이터프레임으로 정리
-데이터 프레임 생성:
importance_df = pd.DataFrame({'Feature': X_train.columns, 'Importance': importances})- X_train.columns는 학습 데이터에서 사용된 모든 특징의 이름을 가져오기
- importances는 모델에서 계산된 각 특징의 중요도를 담고 있는 것
- 이 두 정보를 기반으로 Feature와 Importance라는 두 개의 열을 가진 데이터프레임을 만들기
-중요도 순으로 정렬:
.sort_values(by='Importance', ascending=False)- Importance 열을 기준으로 내림차순(ascending=False)으로 정렬하고 이를 통해 가장 중요한 특징이 상단에 오도록 정리
이렇게 주제를 정하고 나서 팀원분들과 전처리와 변수의 중요도까지 한 번 진행해봤다.
기초프로젝트와 달리 어렵고 막막했던 점들이 많았고 .... 아마 튜터님께 많이 찾아가지 않을까 싶다 😂😂
아직 이상치 확인 및 처리와 스케일링, 시각화, 모델링이 남아있기 때문에 열심히 진행해 볼 예정이다 !
'Project' 카테고리의 다른 글
| [심화 프로젝트] 이커머스 주간 판매량 예측3 (0) | 2024.08.30 |
|---|---|
| [심화 프로젝트] 이커머스 주간 판매량 예측2 (1) | 2024.08.28 |
| [기초 프로젝트] END! + 피드백 (0) | 2024.07.29 |
| [기초 프로젝트] DAY 3 (1) | 2024.07.26 |
| [기초 프로젝트] DAY 2 (0) | 2024.07.25 |