
20240927 TIL
실전 프로젝트 렛츠 고
태블로 대시보드를 만들어서 내는 실전 프로젝트를 진행했다
태블로를 배우는 기간이 일주일이라서 조금 막막하긴 했지만 잘 끝냈다!
1. 주제 선정
아마존 데이터 속으로 떠나는 인사이트 모험이라는 주제를 선정했다
원래 처음에는 게임 데이터를 선택했지만 데이터 자체에서 어떤 것을 뽑아낼 수 있을지도 모르겠고 너무 데이터의 크기가 작은 것 같아
급히 아마존 데이터로 변경했다 .....
https://teamsparta.notion.site/7feb0e96febc41fd8353f9c0860a08a6
아마존 데이터 속으로 떠나는 인사이트 모험 | Notion
개요
teamsparta.notion.site
[프로젝트 배경]
아마존의 이커머스 시장이 성장함에 따라 데이터 기반의 재고관리 및 고객관리가 중요
[프로젝트 목적]
1. 전사적인 고객 이해도 제고
2. 실시간 모니터링 및 리스크 관리
3. 비용 절감 및 효율성 증대
[기대 효과]
1. 영업팀 및 마케팅 유관 부서의 데이터 기반 전략 수립
2. 리스크 조기 대응
3. 프로모션 및 캠페인 비용 절감
[선정 이유]
이번 실전 프로젝트때에는 주제가 많지 않았다.
커머스데이터, 주식데이터, 게임데이터, 유저행동데이터 분석 데이터 이렇게 있었는데
주식은 팀원분들께서 다 원하지 않았고 나도 주식에 관심이 없었고 도메인 지식도 부족했기에 선택하지 않았다
유저행동데이터는 기초 프로젝트때 사용해본 데이터라 하고 싶진 않았다
그러다보니 다수결로 자연스럽게 아마존 데이터를 사용하여 프로젝트를 진행하기로 했다!
[프로젝트 명]
전사적 대시보드 공유를 통한 기업의 데이터 드리븐 문화 조성
2. 데이터 뜯어보기
- Custkey
- 설명: 각 고객을 고유하게 식별하는 키입니다. 특정 고객의 구매 패턴을 추적할 수 있습니다.
- 예시: 10016609
- DateKey
- 설명: 데이터가 기록된 날짜로, 거래가 발생한 날짜를 나타냅니다.
- 형식: MM/DD/YYYY
- 예시: 12/31/2019
- Discount Amount
- 설명: 각 거래에서 적용된 할인 금액입니다. 할인이 없는 경우 0이 될 수 있습니다.
- 예시: 398.73
- Invoice Date
- 설명: 송장이 발행된 날짜로, 고객에게 송장이 발송된 날짜입니다.
- 형식: YYYY/MM/DD
- 예시: 2019/12/31
- Invoice Number
- 설명: 송장의 고유 번호입니다. 거래를 고유하게 식별하는 데 사용됩니다.
- 예시: 329568
- Item Class
- 설명: 상품의 분류를 나타내는 코드입니다. 특정 카테고리나 유형의 상품을 분류합니다.
- 예시: P01
- Item Number
- 설명: 각 상품의 고유 번호로, 특정 상품을 식별하는 데 사용됩니다.
- 예시: 15640
- Item
- 설명: 판매된 상품의 이름입니다. 상품의 특성과 종류를 나타냅니다.
- 예시: Super Vegetable Oil
- Line Number
- 설명: 주문 내 각 상품 라인의 번호로, 주문서 내 여러 상품의 순서를 나타냅니다.
- 예시: 1000
- List Price
- 설명: 상품의 정가입니다. 할인 전의 원래 가격을 나타냅니다.
- 예시: 163.47
- Order Number
- 설명: 주문 번호로, 고객의 각 주문을 고유하게 식별하는 번호입니다.
- 예시: 122380
- Promised Delivery Date
- 설명: 고객에게 약속된 배송 날짜입니다. 이 날짜까지 상품이 배송될 것으로 예상됩니다.
- 형식: MM/DD/YYYY
- 예시: 12/31/2019
- Sales Amount
- 설명: 각 거래의 실제 판매 금액입니다. 할인 후의 최종 금액을 나타냅니다.
- 예시: 418.62
- Sales Amount Based on List Price
- 설명: 정가를 기준으로 한 판매 금액입니다. 할인이 적용되지 않은 경우의 판매 금액을 나타냅니다.
- 예시: 817.35
- Sales Cost Amount
- 설명: 각 거래의 판매 원가입니다. 상품을 판매하는 데 들어간 비용을 나타냅니다.
- 예시: 102.99
- Sales Margin Amount
- 설명: 각 거래의 판매 마진 금액입니다. 판매 금액에서 판매 원가를 뺀 금액을 나타냅니다.
- 예시: 315.63
- Sales Price
- 설명: 각 상품의 실제 판매 가격입니다. 할인 적용 후의 가격을 나타냅니다.
- 예시: 83.72400
- Sales Quantity
- 설명: 각 거래에서 판매된 상품의 수량입니다. 한 번의 거래에서 몇 개의 상품이 팔렸는지 나타냅니다.
- 예시: 5
- Sales Rep
- 설명: 판매 담당자의 코드와 단위를 나타냅니다. 특정 판매 담당자와 관련된 거래를 식별하는 데 사용됩니다.
- 예시: 176
- U/M
- EA (Each)
- 설명: 개별 단위로 판매된 상품을 나타냅니다. 주로 개별적으로 카운트되는 상품에 사용됩니다.
- 예시: 5 EA는 5개의 상품을 의미합니다.
- 활용 예시:
- 개별 포장된 제품 (예: 음료수 캔, 책)
- 소형 가전제품 (예: 헤어 드라이어, 전기 주전자)
- PR (Pair)
- 설명: 쌍으로 판매된 상품을 나타냅니다. 주로 한 쌍이 한 단위로 판매되는 상품에 사용됩니다.
- 예시: 3 PR은 3쌍의 상품을 의미합니다.
- 활용 예시:
- 신발 (예: 운동화 한 쌍)
- 양말 (예: 양말 한 쌍)
- SE (Set)
- 설명: 세트 단위로 판매된 상품을 나타냅니다. 여러 개의 상품이 하나의 세트로 묶여 판매되는 경우에 사용됩니다.
- 예시: 2 SE는 2세트의 상품을 의미합니다.
- 활용 예시:
- 가구 세트 (예: 식탁 세트, 의자 세트)
- 주방용품 세트 (예: 냄비 세트, 칼 세트)
- EA (Each)
컬럼도 굉장히 많았고 이때까지 프로젝트 하면서 가장 많은 데이터 양이었던 것 같다
앞서 각 컬럼들이 어떤 의미를 가지고 있는지 적어놨지만 사실 비슷한 의미가 많아서 이거랑 저거랑 뭐가 다른거지 ..? 이런 혼란이 있었다..
그래도 게임데이터보단 괜찮겠지하고 선택한거였는데 ... 아마존 데이터도 사실 쉽지 않아보였다 ..
그래도 어떡해 해야지 란 마인드로 시작 !!
3. 데이터 전처리
데이터 전처리는 팀원들마다 각 전처리를 해보고 가장 좋은 의견이 있는 팀원의 뜻을 따르기로 했다
구글 공유시트를 이용해 각자 생각한 전처리를 적고 얘기를 나누는 식으로 진행했다.
그래서 각 좋은 아이디어가 나온 것들을 채택 후 전처리 부분은 팀원 분 한 분께서 맡아서 처리를 해주셨다.
결측치 처리
#데이터 불러오기
raw_data = pd.read_csv('./AmazonFoodCategory Dataset.csv')
print(raw_data.shape)
#(65280, 20)df = raw_data.copy()
df.head(3)
null_df = pd.concat([df.isnull().sum(), df.isnull().sum() / len(df)], axis = 1)
null_df.columns = ['num', 'ratio']
null_df[null_df['num'] > 0]
# 결측치 처리
# 1. Item Number, Item Class : 필요 없는 변수 (거의 모든 값이 P01) -> Custom 으로 Class 를 만들것
# 2. Discount Amount, Sales Price -> 행 삭제 (결측치 수가 적고)
# Item Number, Item Class 컬럼 제거
df.drop(['Item Number', 'Item Class'], axis = 1, inplace = True)
# Discount Amount, Sales Price 행 제거
df.dropna(inplace = True)
df.shape # 65,280 -> 65,278
#결과 값 : (65278, 18)# 결측치 확인
null_df = pd.concat([df.isnull().sum(), df.isnull().sum() / len(df)], axis = 1)
null_df.columns = ['num', 'ratio']
null_df[null_df['num'] > 0]이상치 및 데이터 클리닝
Custom Item Class 추가
Promised Delivery Date 가 DateKey 날짜보다 빠른 경우 DateKey 일자와 동일한 값으로 정리하기.
U/M 동일 아이템명을 가진 데이터를 참고해서 변경 ('EA')
1. 아이템 별로 카테고리 나눠주기
너무 많은 각각의 아이템들이 많았기 때문에 카테고리 파생변수를 만들어서 입력해줬다
카테고리는 각 아이템들의 특징을 보고 나눴고 각 팀원분들이 130개 정도씩 아이템을 맡아 각 맞는 카테고리를 지정했다.
지정하는 것도 공유 엑셀 파일을 통해 만들었다
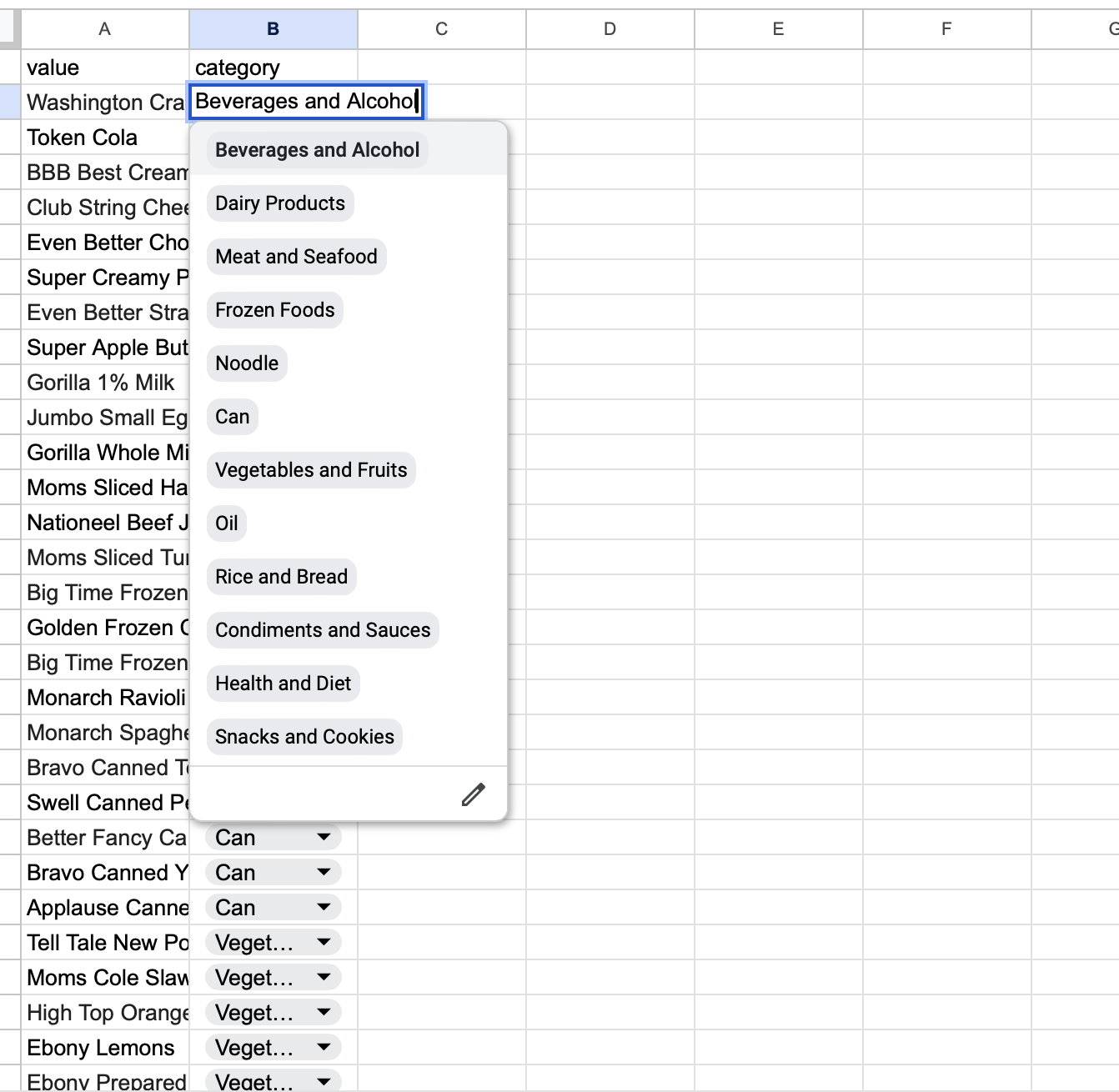
# 카테고리를 만든 구글시트 불러오기
import gspread
import google
from google.auth.transport.requests import Request
from google.colab import auth
from oauth2client.service_account import ServiceAccountCredentials
# 사용자 인증
auth.authenticate_user()
# 인증 스코프 설정 (Google Drive와 Google Sheets에 접근 권한)
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
# 인증 정보 설정 (만약 Service Account 사용 시, JSON 키 파일을 사용해도 됩니다)
creds, _ = google.auth.default()
gc = gspread.authorize(creds)
spreadsheet_id = '1XNZfBYFxlDGT_3Zr8bIk0h68uY3tng6NOYAGN70DSkg'
# 스프레드시트 열기
sheet = gc.open_by_key(spreadsheet_id)
# 특정 시트 이름을 지정하여 불러오기
worksheet = sheet.worksheet('category_value(Custom)')
# 시트 데이터 가져오기 (전체 데이터를 가져올 때)
data = worksheet.get_all_values()
# 데이터를 DataFrame으로 변환
custom_category = pd.DataFrame(data[1:], columns=data[0])
# 결측값 처리 (예시)
custom_category.fillna("N/A", inplace=True)
# 전처리된 데이터 확인
custom_category.head()
# 카테고리 추가
df = pd.merge(df, custom_category, left_on = 'Item', right_on = 'value', how = 'left').drop(columns = ['value'])
df.head()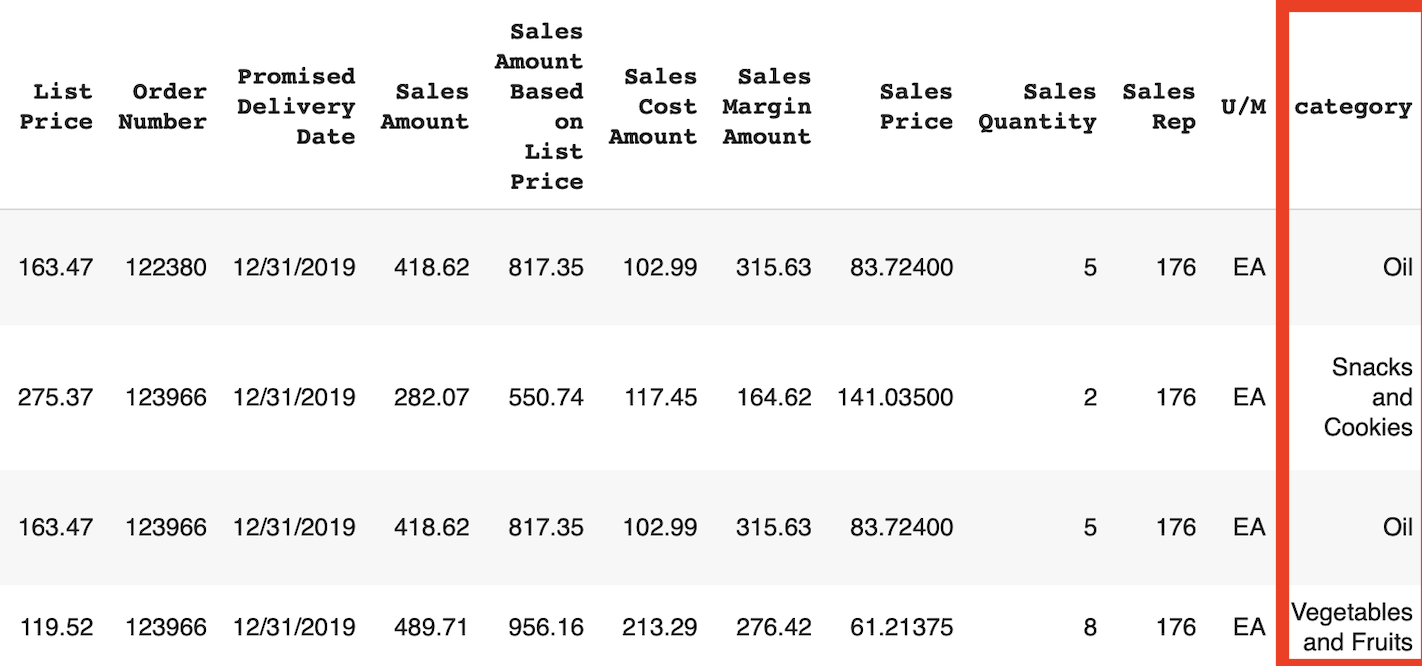
2. Promised Delivery Date 가 DateKey 날짜보다 빠른 경우 DateKey 일자와 동일한 값으로 정리하기.
# DateKey와 Promised Delivery Date가 DateTime 형식으로 되어 있어야 비교가 가능
# 만약 문자열로 되어 있다면, DateTime으로 변환
df['DateKey'] = pd.to_datetime(df['DateKey'])
df['Promised Delivery Date'] = pd.to_datetime(df['Promised Delivery Date'])# Promised Delivery Date가 DateKey보다 빠른 경우 필터링
invalid_dates = df[df['Promised Delivery Date'] < df['DateKey']]
# 그런 경우들이 몇 개인지 보여줌
print(f"Promised Delivery Date가 DateKey보다 빠른 경우는 {len(invalid_dates)}개입니다.")
# Promised Delivery Date가 DateKey보다 빠른 경우는 8968개입니다.# Promised Delivery Date가 DateKey보다 빠른 경우, Promised Delivery Date를 DateKey와 동일하게 변경
df.loc[df['Promised Delivery Date'] < df['DateKey'], 'Promised Delivery Date'] = df['DateKey']
# 변경 후 확인
print("변경 완료!")
df.head() # df에서 변경된 결과 일부 확인
# 변경 완료!3. U/M 동일 아이템명을 가진 데이터를 참고해서 변경 ('EA')
# U/M value count
df['U/M'].value_counts()
# '-' 값이 있는 행 찾기
invalid_um_rows = df[df['U/M'] == '-']
# 동일한 Item에 대한 UM 값으로 대체
for idx, row in invalid_um_rows.iterrows():
# 동일한 Item의 다른 행에서 UM 값을 찾음
correct_um = df[(df['Item'] == row['Item']) & (df['U/M'] != '-')]['U/M'].values
if len(correct_um) > 0:
# 첫 번째로 발견된 UM 값으로 대체
df.at[idx, 'U/M'] = correct_um[0]# U/M value count
df['U/M'].value_counts()
4. 2018년 데이터 제거
아마존 푸드 카테고리 데이터는 2017~2019년까지 데이터가 있는데 그 중 2018년만 1~3월까지의 데이터만 존재했어서
우리는 2017년과 2019년만 비교하자라고 얘기를 나눠서 2018년 데이터는 삭제 해줬다
df = df[df['DateKey'].dt.year != 2018]
# 잘 처리되었는지 확인
# 2018년 데이터 제거
df_filtered = df[df['DateKey'].dt.year != 2018]
# 2018년 데이터가 제거되었는지 확인 (2018년 데이터가 존재하지 않아야 함)
if df_filtered[df_filtered['DateKey'].dt.year == 2018].empty:
print("2018년 데이터가 성공적으로 제거되었습니다.")
else:
print("2018년 데이터가 여전히 존재합니다.")
# 2018년 데이터가 성공적으로 제거되었습니다.5. 공휴일 변수 추가
# !pip install holidays
import holidays
# 2017년도 미국 공휴일 리스트 생성
us_holidays = holidays.US(years=[2017, 2019])
# 공휴일 여부를 확인하는 함수
def is_holiday(date):
return date in us_holidays
# 공휴일 이름을 반환하는 함수
def get_holiday_name(date):
return us_holidays.get(date) if date in us_holidays else None
# 'IsHoliday' 컬럼 추가 (True/False)
df['IsHoliday'] = df['DateKey'].apply(is_holiday)
# 'HolidayName' 컬럼 추가 (공휴일 이름)
df['HolidayName'] = df['DateKey'].apply(get_holiday_name)
# 공휴일인 행만 필터링
holiday_df = df[df['IsHoliday'] == True]
print(holiday_df.shape)
holiday_df.head(1)

# 공휴일 날짜의 고유한 값 추출
unique_holiday_dates = holiday_df['DateKey'].unique()
unique_holiday_name = holiday_df['HolidayName'].unique()
# 결과 출력
print("Unique Holiday Dates:")
print(unique_holiday_dates)
# 공휴일 데이터와 공휴일 이름 확인
print("\nHoliday Name:")
print(unique_holiday_name)
6. 고객별 누계 (3, 5, 7) stage 라벨 부여 + 기준점 출력
df = pd.read_csv('preprocessed_data.csv')
df['DateKey'] = pd.to_datetime(df['DateKey'])-카테고리별 누계 (3, 5, 7) stage 라벨 부여
import pandas as pd
# 경계값들을 저장할 빈 리스트 생성
boundary_dict = {}
# 고객별 Sales Amount 누계
df_customer_sum = df.groupby('Custkey')['Sales Amount'].sum().reset_index()
# 3개, 5개, 7개 그룹화하여 라벨링 및 경계값 저장
df_customer_sum['Sales_3_Group'], bins_3 = pd.qcut(df_customer_sum['Sales Amount'], q=3, labels=[1, 2, 3], retbins=True)
df_customer_sum['Sales_5_Group'], bins_5 = pd.qcut(df_customer_sum['Sales Amount'], q=5, labels=[1, 2, 3, 4, 5], retbins=True)
df_customer_sum['Sales_7_Group'], bins_7 = pd.qcut(df_customer_sum['Sales Amount'], q=7, labels=[1, 2, 3, 4, 5, 6, 7], retbins=True)
# 경계값 저장
boundary_dict['Customer_3_Groups'] = bins_3
boundary_dict['Customer_5_Groups'] = bins_5
boundary_dict['Customer_7_Groups'] = bins_7
# 고객별 누계 정보를 원래 df에 병합
df = pd.merge(df, df_customer_sum[['Custkey', 'Sales_3_Group', 'Sales_5_Group', 'Sales_7_Group']], on='Custkey', how='left')
# 2017년 데이터 처리
df_2017 = df[df['DateKey'].dt.year == 2017]
df_customer_sum_2017 = df_2017.groupby('Custkey')['Sales Amount'].sum().reset_index()
df_customer_sum_2017['Sales_3_Group_2017'], bins_3_2017 = pd.qcut(df_customer_sum_2017['Sales Amount'], q=3, labels=[1, 2, 3], retbins=True)
df_customer_sum_2017['Sales_5_Group_2017'], bins_5_2017 = pd.qcut(df_customer_sum_2017['Sales Amount'], q=5, labels=[1, 2, 3, 4, 5], retbins=True)
df_customer_sum_2017['Sales_7_Group_2017'], bins_7_2017 = pd.qcut(df_customer_sum_2017['Sales Amount'], q=7, labels=[1, 2, 3, 4, 5, 6, 7], retbins=True)
# 경계값 저장
boundary_dict['Customer_3_Groups_2017'] = bins_3_2017
boundary_dict['Customer_5_Groups_2017'] = bins_5_2017
boundary_dict['Customer_7_Groups_2017'] = bins_7_2017
# 2017년 고객별 누계 정보를 원래 df에 병합
df = pd.merge(df, df_customer_sum_2017[['Custkey', 'Sales_3_Group_2017', 'Sales_5_Group_2017', 'Sales_7_Group_2017']], on='Custkey', how='left')
# 2019년 데이터 처리
df_2019 = df[df['DateKey'].dt.year == 2019]
df_customer_sum_2019 = df_2019.groupby('Custkey')['Sales Amount'].sum().reset_index()
df_customer_sum_2019['Sales_3_Group_2019'], bins_3_2019 = pd.qcut(df_customer_sum_2019['Sales Amount'], q=3, labels=[1, 2, 3], retbins=True)
df_customer_sum_2019['Sales_5_Group_2019'], bins_5_2019 = pd.qcut(df_customer_sum_2019['Sales Amount'], q=5, labels=[1, 2, 3, 4, 5], retbins=True)
df_customer_sum_2019['Sales_7_Group_2019'], bins_7_2019 = pd.qcut(df_customer_sum_2019['Sales Amount'], q=7, labels=[1, 2, 3, 4, 5, 6, 7], retbins=True)
# 경계값 저장
boundary_dict['Customer_3_Groups_2019'] = bins_3_2019
boundary_dict['Customer_5_Groups_2019'] = bins_5_2019
boundary_dict['Customer_7_Groups_2019'] = bins_7_2019
# 2019년 고객별 누계 정보를 원래 df에 병합
df = pd.merge(df, df_customer_sum_2019[['Custkey', 'Sales_3_Group_2019', 'Sales_5_Group_2019', 'Sales_7_Group_2019']], on='Custkey', how='left')
df.head(3)
# 카테고리별 Sales Amount 누계
df_category_sum = df.groupby('category')['Sales Amount'].sum().reset_index()
df_category_sum['Sales_3_Group_cat'], bins_category_3 = pd.qcut(df_category_sum['Sales Amount'], q=3, labels=[1, 2, 3], retbins=True)
df_category_sum['Sales_5_Group_cat'], bins_category_5 = pd.qcut(df_category_sum['Sales Amount'], q=5, labels=[1, 2, 3, 4, 5], retbins=True)
df_category_sum['Sales_7_Group_cat'], bins_category_7 = pd.qcut(df_category_sum['Sales Amount'], q=7, labels=[1, 2, 3, 4, 5, 6, 7], retbins=True)
# 경계값 저장
boundary_dict['Category_3_Groups_cat'] = bins_category_3
boundary_dict['Category_5_Groups_cat'] = bins_category_5
boundary_dict['Category_7_Groups_cat'] = bins_category_7
# 카테고리별 누계 정보를 원래 df에 병합
df = pd.merge(df, df_category_sum[['category', 'Sales_3_Group_cat', 'Sales_5_Group_cat', 'Sales_7_Group_cat']], on='category', how='left')
# 2017년 카테고리별 처리
df_category_2017 = df[df['DateKey'].dt.year == 2017].groupby('category')['Sales Amount'].sum().reset_index()
df_category_2017['Sales_3_Group_2017_cat'], bins_category_3_2017 = pd.qcut(df_category_2017['Sales Amount'], q=3, labels=[1, 2, 3], retbins=True)
df_category_2017['Sales_5_Group_2017_cat'], bins_category_5_2017 = pd.qcut(df_category_2017['Sales Amount'], q=5, labels=[1, 2, 3, 4, 5], retbins=True)
df_category_2017['Sales_7_Group_2017_cat'], bins_category_7_2017 = pd.qcut(df_category_2017['Sales Amount'], q=7, labels=[1, 2, 3, 4, 5, 6, 7], retbins=True)
# 경계값 저장
boundary_dict['Category_3_Groups_2017_cat'] = bins_category_3_2017
boundary_dict['Category_5_Groups_2017_cat'] = bins_category_5_2017
boundary_dict['Category_7_Groups_2017_cat'] = bins_category_7_2017
# 2017년 카테고리별 정보를 원래 df에 병합
df = pd.merge(df, df_category_2017[['category', 'Sales_3_Group_2017_cat', 'Sales_5_Group_2017_cat', 'Sales_7_Group_2017_cat']], on='category', how='left')
# 2019년 카테고리별 처리
df_category_2019 = df[df['DateKey'].dt.year == 2019].groupby('category')['Sales Amount'].sum().reset_index()
df_category_2019['Sales_3_Group_2019_cat'], bins_category_3_2019 = pd.qcut(df_category_2019['Sales Amount'], q=3, labels=[1, 2, 3], retbins=True)
df_category_2019['Sales_5_Group_2019_cat'], bins_category_5_2019 = pd.qcut(df_category_2019['Sales Amount'], q=5, labels=[1, 2, 3, 4, 5], retbins=True)
df_category_2019['Sales_7_Group_2019_cat'], bins_category_7_2019 = pd.qcut(df_category_2019['Sales Amount'], q=7, labels=[1, 2, 3, 4, 5, 6, 7], retbins=True)
# 경계값 저장
boundary_dict['Category_3_Groups_2019'] = bins_category_3_2019
boundary_dict['Category_5_Groups_2019'] = bins_category_5_2019
boundary_dict['Category_7_Groups_2019'] = bins_category_7_2019
# 2019년 카테고리별 정보를 원래 df에 병합
df = pd.merge(df, df_category_2019[['category', 'Sales_3_Group_2019_cat', 'Sales_5_Group_2019_cat', 'Sales_7_Group_2019_cat']], on='category', how='left')
7. 누계 경계값 출력
# 지수 표기법을 사용하지 않도록 설정
pd.set_option('display.float_format', '{:.2f}'.format)
# 경계값 딕셔너리를 DataFrame으로 변환
boundary_df = pd.DataFrame({key: pd.Series(value) for key, value in boundary_dict.items()})
boundary_df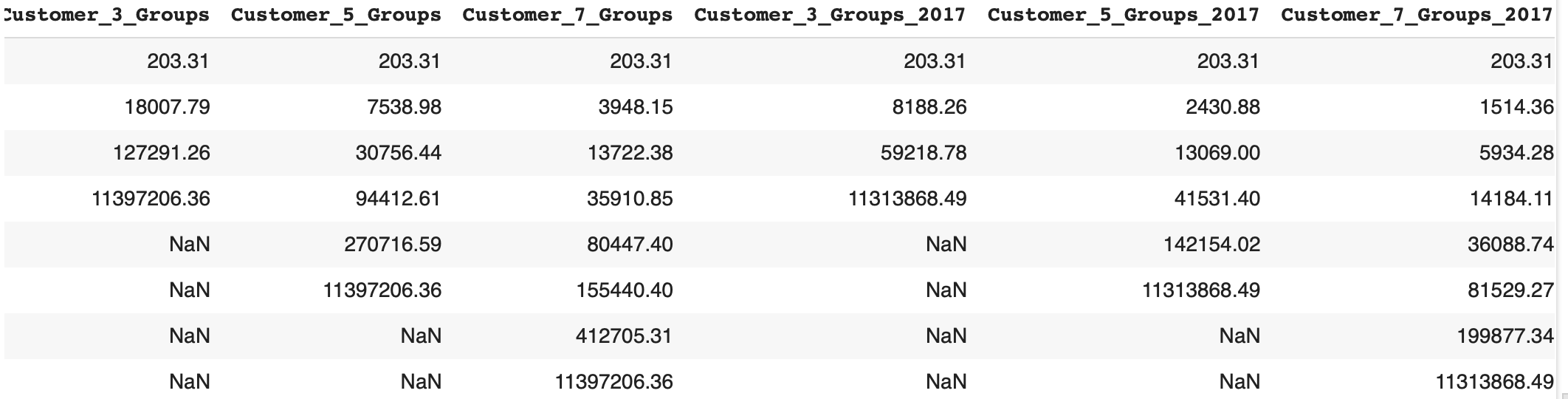
8. 데이터 저장
df.to_csv('preprocessed_data.csv', index = False)
boundary_df.to_csv('boundary.csv', index = False)데이터 전처리 부분도 원래 이렇게까지 나눠지진 않았었는데 막상 데이터를 어떻게 할지 생각하다가
파생변수들이 점점 늘어가게 되면서 이렇게 많아졌다
나였더라면 이렇게 깔끔하게 데이터 전처리와 클리닝 한 부분을 정리하지 못했을 것 같은데 정말 팀원분께서 열심히 노력하신게 티가 난다
난 아직은 이만큼은 안되지만 꼭 이만큼도 바라지 않으니 좀 더 실력이 향상 됐으면 좋겠다
나머지 부분도 이어서 블로그 작성 할 예정이다
'Project' 카테고리의 다른 글
| [실전 프로젝트] 아마존 데이터 속으로 떠나는 인사이트 모험2 (1) | 2024.11.11 |
|---|---|
| [심화 프로젝트] 이커머스 주간 판매량 예측 - 피드백 (2) | 2024.11.07 |
| [심화 프로젝트] 이커머스 주간 판매량 예측3 (0) | 2024.08.30 |
| [심화 프로젝트] 이커머스 주간 판매량 예측2 (2) | 2024.08.28 |
| [심화프로젝트] 이커머스 주간 판매량 예측1 (0) | 2024.08.23 |