20240717 TIL
00. 데이터 전처리
▶데이터 전처리
- 내가 원하는 데이터를 보기 위해 하는 모든 활동
▶ 데이터셋 불러오기
Seaborn이라는 라이브러리에서 불러올 수 있는 내장데이터 셋
iris - 붓꽃의 꽃잎과 꽃받침의 길이와 너비를 포함한 데이터셋
tips - 음식점에서의 팁과 관련된 정보를 담고 있는 데이터셋
titanic - 타이타닉 호 승객들의 정보를 포함한 데이터셋
flights - 연도별 항공편 정보를 담고 있는 데이터셋
planets - 외계 행성 발견에 대한 정보를 담고 있는 데이터셋
import seaborn as sns
# 'tips' 데이터셋 불러오기
tips_data = sns.load_dataset('tips')
# 데이터셋 확인
print(tips_data.head())
01. Pandas 알아보기
Pandas?
- Python에서 데이터를 조작하고 쉽게 분석할 수 있게 도와주는 라이브러리
- 대규모 데이터셋 및 복잡한 작업을 처리하는 데 효과적이며, 자동화와 프로그래밍 기능을 통해 더 많은 유연성과 확장성 제공
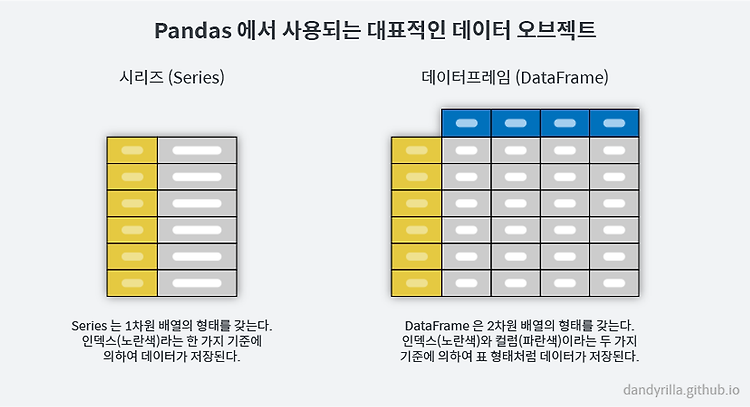
▶ Pandas 구조

DataFrame = 표 형태
- index: 각 아이템을 특정할 수 있는 고유의 값
- columns: 하나의 속성을 가진 데이터 집합
Series = 하나의 속성을 가진 데이터 집합(= DataFrame 표에서 열 1줄이라고 생각하면 쉬움)
- value + index
▶ Pandas 불러오기
import pandas as pd
# pandas 라이브러리를 불러올 것이며 이제부터 pandas를 pd라고 부를게 !
# 에러날 경우 !pip install pandas #실행
02. 데이터 불러오기/저장하기
▶ 엑셀/CSV 데이터 불러오기
# pd.read_excel('파일경로/파일명.확장자')
# 엑셀 불러오기
pd.read_excel('./파일명.xlsx') # ./ ==> 현재 내가 있는 위치라는 의미
# csv 파일 불러오기
pd.read_csv('./파일명.xlsx')▶ 인덱스
# Pandas에서 사용자가 직접 설정한 인덱스를 변경하는 예시
import pandas as pd
# 사용자가 직접 인덱스를 설정한 데이터프레임 생성
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']}, index=['idx1', 'idx2', 'idx3'])
# 인덱스 변경 (대체)
df.index = ['new_idx1', 'new_idx2', 'new_idx3']
print(df)
-인덱스 활용하기
df = pd.DataFrame({
'A': [1,2,3],
'B': ['a', 'b', 'c']
},index=['idx1', 'idx2', 'idx3'])
df.loc['idx2'] #그 인덱스에 맞는 정보 가져오기
df.sort_index() #정렬
df.set_index('A') #특정 컬럼명을 기준으로 인덱스 설정
df.index = ['1', '2', '3'] #리스트 형태를 활용하여 인덱스 새로 입력하기
df.reset_index() #현재 인덱스를 0부터 시작하는 정수로 변경 가능
df.reset_index(drop=True) #현재 인덱스 값을 컬럼으로 변경하지 않고 인덱스 초기화▶ 컬럼(Column)
import pandas as pd
# 데이터프레임 생성
data = {
'이름': ['Alice', 'Bob', 'Charlie'],
'나이': [25, 30, 35],
'성별': ['여', '남', '남']
}
df = pd.DataFrame(data)
# 각 컬럼 출력
print(df['이름']) # '이름' 컬럼 출력
print(df['나이']) # '나이' 컬럼 출력
print(df['성별']) # '성별' 컬럼 출력
-컬럼 활용하기
df = df.rename(columns = {'이름' : 'name'}) #이름 다시 설정하기
df['스포츠'] = '축구' #새로운 인덱스 추가하기▶ 데이터 저장하기
- pd.to_csv(’파일경로/파일명.확장자’ , index = False)
- pd.to_excel(’파일경로/파일명.확장자’ , index = False)
df = 데이터프레임 # 저장하고 싶은 데이터
df.to_csv('./newfile.csv', index = False)
03. 데이터 확인
▶ .head(): 데이터를 N개 행까지 보여줌
data.head() # head()은 기본 5개 행에 대한 데이터를 보여줌
data.head(3) # ()안에 숫자만큼 데이터를 보여줌▶ .info() : 데이터 정보 파악
data.info()
# null 값을 확인할때도 활용▶ .describe() : 데이터의 기초통계량 확인(숫자타입들만)
data.describe()
# 숫자값에 대해서만 기초통계량 확인이 가능합니다.▶ 데이터 타입 변경
astype() : 데이터프레임의 열의 데이터 타입을 변경하는 데 사용
DataFrame['column_name'] = DataFrame['column_name'].astype(new_dtype)DataFrame['column_name'] : 열을 선택한느 방식 / 열의 데이터 타입을 변경하고자 하는 열을 지정
new_dtype : 변경하고자 하는 새로운 데이터 타입을 명시
<예시들>
<예시1> int --> float
import pandas as pd
# 예시 데이터프레임 생성
data = {'integer_column': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
# 정수형 열을 부동소수점으로 변환
df['integer_column'] = df['integer_column'].astype(float)
print(df.dtypes) # 데이터프레임의 열 타입 확인
<예시2> int --> str
import pandas as pd
# 예시 데이터프레임 생성
data = {'numeric_column': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
# 숫자열을 문자열로 변환
df['numeric_column'] = df['numeric_column'].astype(str)
print(df.dtypes) # 데이터프레임의 열 타입 확인04. 데이터 선택
▶ .iloc[로우, 컬럼] : 인덱스 번호로 선택하기
data.iloc[0,2]
#행과 열 번호를 통해 특정 데이터를 선택할 수 있음
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data)
# iloc을 사용하여 특정 행과 열 선택
selected_data = df.iloc[1:4, 0:2] # 인덱스 1부터 3까지의 행과 0부터 1까지의 열 선택
print(selected_data)
# 활용하기
df.iloc[0]
df.iloc[0:2]
df.iloc[0:4:2]
df.iloc[0, 0:2]▶ .loc[로우,컬럼] : 이름으로 선택하기 --> 인덱스 번호가 아니라 특정 문자일 경우
data.loc['행이름' , '컬럼명']
# 행이름과 컬럼명을 통해서도 특정 데이터를 선택할 수 있음
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# loc을 사용하여 특정 행과 열 선택
selected_data = df.loc['b':'d', 'A':'B'] # 레이블 'b'부터 'd'까지의 행과 'A'부터 'B'까지의 열 선택
print(selected_data)▶ slicing, selection
df = pd.DataFrame({
'A': [1,2,3,4,5],
'B': [10,20,30,40,50],
'C': [100,200,300,400,500]
}, index=['a','b','c','d','e'])
df.loc[:, 'A']
df['A']
df[['A', 'B']] #순서 변경도 가능
df.loc['a':, ['A', 'C']]<df 데이터 프레임>
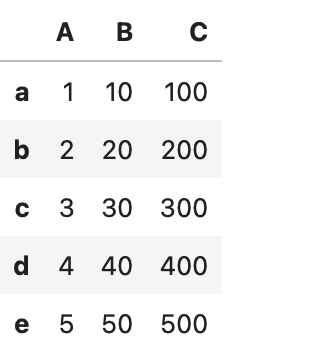

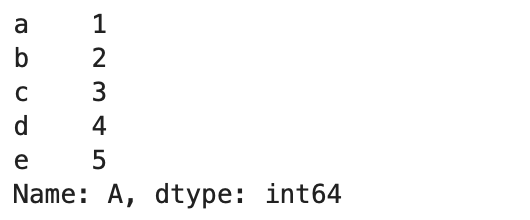
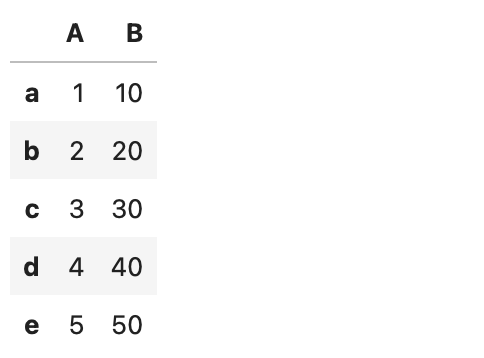

▶ Boolean indexing
df = pd.read_csv("temp/tips_data.csv")
df[df['sex'] == 'Male'] # 성별에 Male만 나옴
df[(df['sex'] == 'Male') & (df['smoker'] == 'Yes')] # 성별이 Male이고 smoker인 사람
df[(df['sex'] == 'Male') | (df['smoker'] == 'Yes')] #or = |
df.loc[df['size']>3, :] #사이즈가 3이상인 모든 데이터
df.loc[df['size']>3, 'tip':'smoker'] #사이즈가 3보다 큰 tip에서부터 smoker까지 데이터 나옴
df[df['size'].isin([1,2])] # 여러 값 포함 여부 확인isin() - 특정 값이나 리스트 안에 포함된 값들을 찾아내는 메소드 / 조건에 해당하는 데이터를 빠르게 필터링하거나 선택 가능
▶ 데이터 추가하기
df = pd.DataFrame()
df['컬럼명'] = data
# df라는 데이터프레임에 '컬럼명'이라는 이름의 컬럼이 추가되고,해당 컬럼에 data라는 값이 추가된다.
# 이때, data값이 1개의 단일 값인 경우에는 전체 df라는 데이터프레임 행에 data 값이 전체 적용됨
# 즉,
# 하나의 값인 경우 => 전체 모두 동일한 값 적용
# (리스트,시리즈)의 형태인 경우 => 각 순서에 맞게 컬럼 값에 적용됨신규 컬럼 추가하기
df = pd.DataFrame()
# 컬럼 추가하기
df['EPL'] = 100
df['MLS'] = 60
df['NBA'] = 70
df
# 리스트 형태로 컬럼값 추가하기
df['KFC'] = [50, 10, 30]
#Tip. 행 수를 맞춰서 입력해줘야함
# 컬럼을 여러 조건 및 계산식을 통해 산출 값으로도 추가가 가능
df['ABC'] = (df['EPL'] + df['NBA']) * df['MLS'] * 205. 데이터 병합
▶concat() - 데이터프레임을 위아래로 혹은 좌우로 연결 가능
- axis : 연결하고자 하는 축(방향)을 지정, 기본값은 0 --> 위아래로 연결하는 경우 // 1--> 좌우로 연결
- ignore_index : 기본값은 False --> 연결된 결과 데이터프레임의 인덱스 유지 // True --> 새로운 인덱스 생성
import pandas as pd
# 두 개의 데이터프레임 생성
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'], 'B': ['B0', 'B1', 'B2']})
df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'], 'B': ['B3', 'B4', 'B5']})
# 위아래로 데이터프레임 연결
result_vertical = pd.concat([df1, df2], axis=0)
# 좌우로 데이터프레임 연결
result_horizontal = pd.concat([df1, df2], axis=1)
print("위아래 연결 결과:\n", result_vertical)
print("\n좌우 연결 결과:\n", result_horizontal)▶ merge() - SQL의 join 연산과 유사한 방식 / 주로 두 개 이상의 데이터프레임에서 공통된 열이나 인덱스를 기준으로 데이터 병합
- left, right : 병합되는 기준
- how : 병합 방법을 나타내는 매개변수 --> inner, outer, left, right
- inner -- 공통된 키를 기준으로 교집합
- outer -- 공통된 키를 기준으로 합집합
- on : 병합 기준이 되는 열 이름(혹은 열 이름의 리스트)을 지정 / left_on, right_on에서 병합할 열 이름이 다른 경우 사용

import pandas as pd
# 두 개의 데이터프레임 생성
left_df = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
right_df = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': [5, 6, 7, 8]})
# 'key' 열을 기준으로 두 데이터프레임 병합
merged_df = pd.merge(left_df, right_df, on='key', how='inner')
print(merged_df)
06. 데이터 집계
▶ groupby()
데이터프레임을 그룹화하고, 그룹 단위로 데이터를 분할, 적용, 결합하는 기능을 제공
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Value': [1, 2, 3, 4, 5, 6]
}
df = pd.DataFrame(data)
# 'Category' 열을 기준으로 그룹화하여 'Value'의 연산 수행
grouped = df.groupby('Category').mean()
grouped_sum = df.groupby('Category').sum()
grouped_count = df.groupby('Category').count()
grouped_max = df.groupby('Category').max()
grouped_min = df.groupby('Category').min()
# 수치형 데이터의 경우에 연산이 가능복수의 열을 기준
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'Category': ['A', 'A', 'B', 'B', 'A', 'B'],
'SubCategory': ['X', 'Y', 'X', 'Y', 'X', 'Y'],
'Value': [1, 2, 3, 4, 5, 6]
}
df = pd.DataFrame(data)
# 'Category'와 'SubCategory' 열을 기준으로 그룹화하여 'Value'의 합 계산
grouped_multiple = df.groupby(['Category', 'SubCategory']).sum()
print(grouped_multiple)다양한 집계 함수 적용
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'Category': ['A', 'A', 'B', 'B', 'A', 'B'],
'SubCategory': ['X', 'Y', 'X', 'Y', 'X', 'Y'],
'Value1': [1, 2, 3, 4, 5, 6],
'Value2': [10, 20, 30, 40, 50, 60]
}
df = pd.DataFrame(data)
# 'Category'와 'SubCategory' 열을 기준으로 그룹화하여 각 그룹별 'Value1'과 'Value2'의 평균, 합 계산
grouped_multiple = df.groupby(['Category', 'SubCategory']).agg({'Value1': ['mean', 'sum'], 'Value2': 'sum'})
print(grouped_multiple)▶ Pivot Table()
데이터를 재구성하여 요약, 집계된 정보를 보여주는 테이블 형태
피벗테이블 생성하기
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'],
'Category': ['A', 'B', 'A', 'B', 'A'],
'Value': [10, 20, 30, 40, 50]
}
df = pd.DataFrame(data)
# 피벗 테이블 생성: 날짜를 행 인덱스로, 카테고리를 열 인덱스로, 값은 'Value'의 합으로 집계
pivot = df.pivot_table(index='Date', columns='Category', values='Value', aggfunc='sum')
print(pivot)여러 열을 기준
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'],
'Category': ['A', 'B', 'A', 'B', 'A'],
'SubCategory': ['X', 'Y', 'X', 'Y', 'X'],
'Value': [10, 20, 30, 40, 50]
}
df = pd.DataFrame(data)
# 피벗 테이블 생성: 'Date'를 행 인덱스로, 'Category'와 'SubCategory'를 열 인덱스로, 값은 'Value'의 합으로 집계
pivot = df.pivot_table(index='Date', columns=['Category', 'SubCategory'], values='Value', aggfunc='sum')
print(pivot)집계 함수를 다르게 적용
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'],
'Category': ['A', 'B', 'A', 'B', 'A'],
'Value1': [10, 20, 30, 40, 50],
'Value2': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data)
# 피벗 테이블 생성: 'Date'를 행 인덱스로, 'Category'를 열 인덱스로, 값은 'Value1'과 'Value2'의 평균과 합으로 집계
pivot = df.pivot_table(index='Date', columns='Category', values=['Value1', 'Value2'], aggfunc={'Value1': 'mean', 'Value2': 'sum'})
print(pivot)💡느낀점
처음 pandas를 써봤는데 꽤 흥미로웠다. 뭔가 파이썬과 SQL을 합친 느낌 ...?
뭔가 파이썬이랑 코드가 비슷한듯 달라서 뭔가 더 헷갈려진 느낌이다 ㅠㅠ 물론 하다보면 익숙해져서 괜찮겠지만
데이터 분석가는 pandas를 더 많이 사용한다고 하는데 익숙해질 수 있도록 더 노력해야겠다 ! 복습과 노력만이 살길이다 ^^ ....
처음이라 그런지 몰라도 파이썬보다는 뭔가 더 흥미를 느꼈다 내주시는 숙제들도 혼자 열심히 풀어봐야지!
'✨Today I Learned > Python' 카테고리의 다른 글
| 데이터 전처리 문제 실습 (0) | 2024.07.19 |
|---|---|
| 📊데이터 시각화 (Matplotilb) (0) | 2024.07.18 |
| Python codekata 19번 - 정수 제곱근 판별 (0) | 2024.07.11 |
| 파이썬 라이브 세션 3회차 개인과제 (0) | 2024.07.10 |
| 파이썬 라이브 세션 2일차 퀴즈 (0) | 2024.07.09 |