20240719 TIL
Seaborn 내장데이터 셋을 활용해서 데이터를 전처리 해보자!
Q1. 'species' 열 값이 'setosa'인 데이터 선택하기
import seaborn as sns
iris_data = sns.load_dataset('iris')
setosa_data = iris_data.loc[iris_data['species'] == 'setosa']
print("Setosa 데이터:")
print(setosa_data.head())- 데이터셋 불러오기 --> iris_data = sns.load_dataset('iris')
- 'species' 열 값이 'setosa'인 데이터 선택 --> setosa_data = iris.data.loc[iris_data['species'] == 'setosa]
- 선택된 데이터 확인 --> print("Setosa 데이터:") print(setosa_data.head())
더보기
결과값:
- .loc() --> 특정 조건의 데이터셋 선택
Q2. 10부터 20까지의 행과 1부터 3까지의 열 선택
subset = iris_data.iloc[10:21, 1:4]
print("\nSubset 데이터:")
print(subset)- 10부터 20까지의 행과 1부터 3까지의 열 선택 --> subset = iris_data.iloc[10:21, 1:4]
- 선택된 데이터 확인 --> print("\nSubset 데이터:") print(subset)
더보기
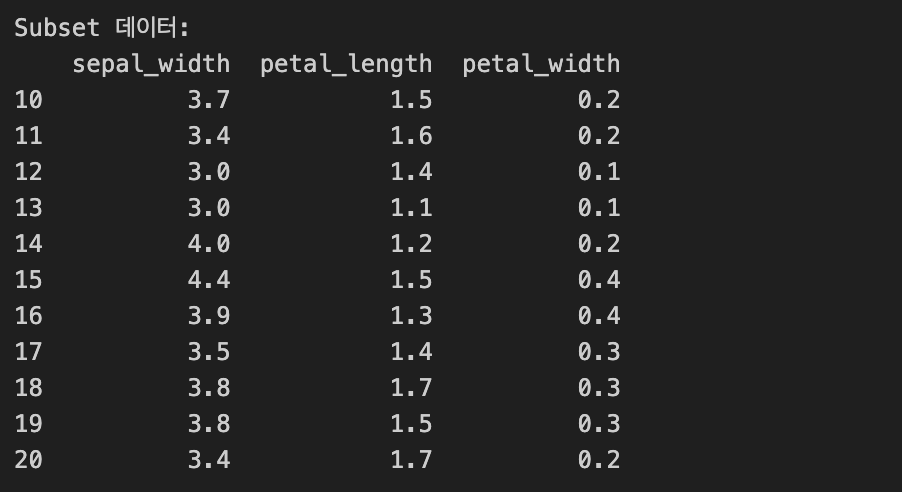
결과값:
.iloc() --> 특정 인덱스 범위의 데이터 선택
| 행만 가져오기 | 행과 열 같이 가져오기 | |
| .loc | df.loc[행이름] df.loc[[행여러개]] df.loc[행슬라이싱] |
df.iloc[인덱스번호] df.iloc[[인덱스번호 여러개]] df.iloc[인덱스번호슬라이싱] |
| .iloc | df.loc[ 행 , 열 ] | df.iloc[ 행 , 열 ] |
| 행,열에는 라벨 , 번호인덱스 모두 가능 슬라이싱의 경우 끝번호,라벨 포함 O |
행,열에는 번호 인덱스만 가능 슬라이싱의 경우 끝번호 포함 X |
|
| 행: 인덱스번호 1개 , [ 인덱스 여러개 ] , [ 인덱스번호 슬라이싱] | 행: 인덱스번호 1개 , [ 인덱스 여러개 ] , [ 인덱스번호 슬라이싱] | |
| 열: 칼럼 1개 , [ 칼럼 여러개 ] , [ 칼럼이름 슬라이싱 ] | 열: 칼럼번호 1개 , [ 칼럼번호 여러개 ] , [ 칼럼번호 슬라이싱 ] |
tips 데이터셋을 활용해서 전처리를 해보자
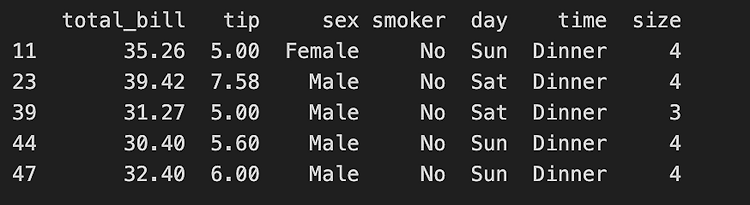
Q1. total_bill이 30 이상인 데이터만 선택하기
import seaborn as sns
tips_data = sns.load_dataset('tips')
total_bills = tips_data.loc[tips_data['total_bill'] >= 30]
print(total_bills.head())- 데이터셋 불러오기 --> tips_data = sns.load_dataset('tips)
- total_bill이 30 이상인 데이터만 선택 --> total_bills = tips_data.loc[tips_data['total_bill'] >= 30]
- 선택된 데이터 가져오기 --> print(total_bills.head())
더보기
결과값:
Q2. 성별('sex')을 기준으로 데이터 그룹화하여 팁(tip)의 평균 계산
grouped = tips_data.groupby('sex')['tip'].mean()
print("\n성별에 따른 팁 평균:")
print(grouped)- 'sex'를 기준으로 데이터 그룹화하여 팁(tip)의 평균 계산 --> grouped = tips_data.groupby('sex')['tip'].mean()
- 그룹화된 데이터의 통계적 요약 확인 --> print("\n성별에 따른 팁 평균:") print(grouped)
더보기

결과값:
groupby() --데이터프레임을 그룹화하고, 그룹 단위로 데이터를 분할(split), 적용(apply), 결합(combine)하는 기능을 제공
Q3. 'day'와 'time'을 기준으로 데이터 그룹화하여 전체 지불 금액(total_bill)의 합 계산
grouped2 = tips_data.groupby(['day', 'time'])['total_bill'].sum()
print("\n요일과 시간별 전체 지불 금액 합계:")
print(grouped2)- 'day'와 'time'을 기준으로 데이터 그룹화하여 전체 지불 금액(total_bill)의 합 계산 -->grouped2 =tips_data.groupby(['day', 'time'])['total_bill'].sum()
- 그룹화된 데이터의 통계적 요약 확인 --> print("\n요일과 시간별 전체 지불 금액 합계:") print(grouped2)
더보기
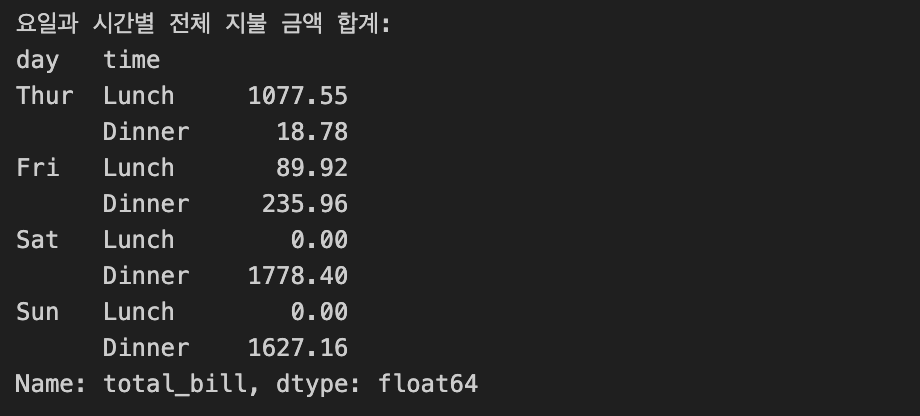
결과값:
Q4. 'day' 열을 기준으로 각 요일별로 팁(tip)의 평균을 새로운 데이터프레임으로 만든 후, 이를 기존의 tips 데이터셋에 합쳐보자
import seaborn as sns
import pandas as pd
tips_data = sns.load_dataset('tips')
print("Tips 데이터셋:")
print(tips_data.head())
avg_tip_per_day = tips_data.groupby('day')['tip'].mean().reset_index()
avg_tip_per_day.columns = ['day', 'avg_tip']
print("\n요일별 평균 팁 데이터:")
print(avg_tip_per_day)
merged_data = pd.merge(tips_data, avg_tip_per_day, on='day', how='left')
print("\n병합된 데이터:")
print(merged_data.head())- 데이터셋 불러오기 --> tips_data = sns.load_dataset('tips')
- 'day'별 평균 팁 데이터 생성 --> avg_tip_per_day = tips_data.groupby('day')['tip'].mean().reset_index()
avg_tip_per_day.columns = ['day', 'avg_tip'] - 'day' 열을 기준으로 기존의 tips 데이터셋과 새로 생성한 데이터셋 merge --> merged_data = pd.merge(tips_data, avg_tip_per_day, on='day', how='left')
- 데이터의 통계적 요약 확인 --> print("\n병합된 데이터:") print(merged_data.head())
더보기
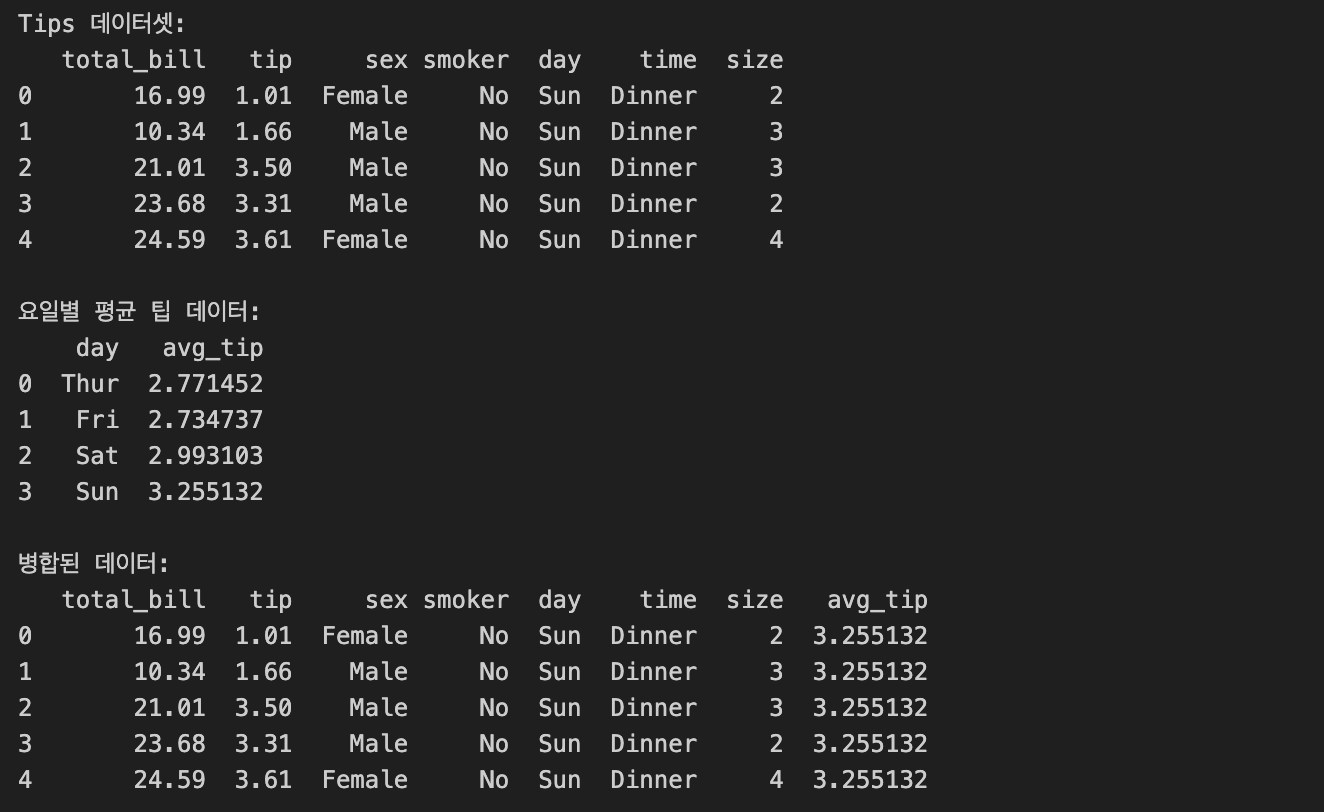
결과값:
merge() -- QL의 JOIN 연산과 유사한 방식으로 데이터프레임을 합칠 수 있다.
- left와 right: 병합할 데이터프레임 중 병합되는 기준이 되는 왼쪽(left)과 오른쪽(right) 데이터프레임
- how: 병합 방법을 나타내는 매개변수로, 'inner', 'outer', 'left', 'right' 등의 옵션이 있다
- 'inner': 공통된 키(열)를 기준으로 교집합을 만든다
- 'outer': 공통된 키를 기준으로 합집합을 만든다
- 'left': 왼쪽 데이터프레임의 모든 행을 포함하고 오른쪽 데이터프레임은 공통된 키에 해당하는 행만 포함
- 'right': 오른쪽 데이터프레임의 모든 행을 포함하고 왼쪽 데이터프레임은 공통된 키에 해당하는 행만 포함
- on: 병합 기준이 되는 열 이름(혹은 열 이름의 리스트)을 지정
- left_on과 right_on: 왼쪽 데이터프레임과 오른쪽 데이터프레임에서 병합할 열 이름이 다른 경우에 사용
💡
확실히 쉽지 않다 .........
개념을 알고 문제를 푸는건데도 잘 모르는게 더 많았다. 그래서 문제를 풀때 계속 개념을 보면서 다시 풀었다.
특히 Q4는 내 기준 좀 어려웠다 ㅠㅠ 내가 만든 코드와 튜터쌤이 만든 코드가 좀 다른데 어쨌거나 결과값은 나왔기 때문이다.
좀 분석을 해봐야 할 것 같다. 그래도 그냥 파이썬보다 코드들이 생소해서 어렵게 느껴지긴 하지만 뭔가 재밌다(나름 희망적 ..)
이대로 열심히 복습하고 노력해야겠다 >,,<
'✨Today I Learned > Python' 카테고리의 다른 글
| [Python] 문자열 내림차순으로 배치하기 (0) | 2024.09.04 |
|---|---|
| 📊데이터 시각화 (Matplotilb) (1) | 2024.07.18 |
| 데이터 전처리 (Pandas) (0) | 2024.07.17 |
| Python codekata 19번 - 정수 제곱근 판별 (1) | 2024.07.11 |
| 파이썬 라이브 세션 3회차 개인과제 (1) | 2024.07.10 |